
[ad_1]
One of many newer knowledge buzzwords is “knowledge debt.” Really, it’s roughly 10 years previous, and it turned well-liked ever since agile folks realized that suspending issues creates not solely technical debt, however definitely additionally knowledge debt. Will we, in 2023, be higher at not creating a lot knowledge debt, and can or not it’s as a result of we are able to come to know stuff simpler (information graphs) or will or not it’s due to with the ability to guess stuff simpler and extra reliably (ML)? Or each?
Allow us to first set a framework for wanting on the points. In January 2021, I posted this: Three Recreation-Altering Information Modeling Views.
Since then the curiosity in making use of ML and AI to “DataOps” within the analytics area has risen to new heights. How does it examine to the game-changing views that I proposed two years in the past?
The three mantras of my January 2021 put up had been:
- Contextualization
- Federated semantics
- Accountability
The patterns are intertwined, actually:
- You need to set up the related context(s)/semantics/accountability necessities,
- Then you should uncover the dependencies between the related elements,
- After which you should examine what you will have by way of specialties with what you should ship by way of a sturdy resolution to the enterprise.
For contexts, we are able to point out specialties akin to traits of dependencies inside and between contexts:
- Cardinalities
- Optionalities
- Inheritance
- Associations, and many others.
For semantics specialties may be traits inside and between semantics:
- Types of illustration
- High quality
- Authoritative and legislatory facets (compliance, and many others.)
- Customary semantic inside business domains, and many others.
- Metadata adjustments
Lastly, for accountability the problems are, inside and between challenge boarders:
- Authoritative and legislator-y facets (“does it maintain in court docket” and many others.)
- Multi-temporality (and adjustments to such schemes over time)
- High quality (of registration and of the accountability)
- Retention
- Metadata adjustments
- Mixture of knowledge with completely different ranges of precision, temporality, and even completely different knowledge varieties
In (very) normal phrases, the considerations may be listed as these:
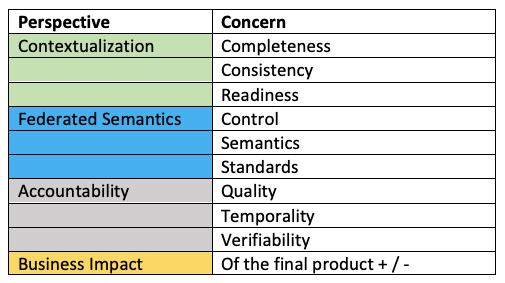
Sadly, the considerations are relying on one another in a posh mesh:
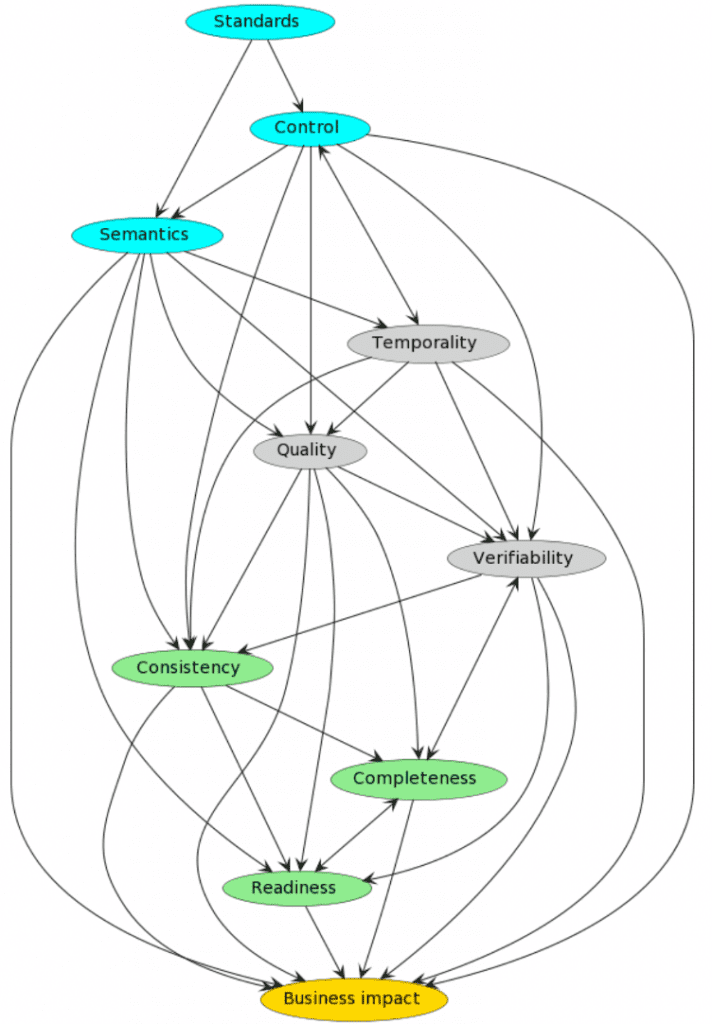
Take some moments to deduce the character of the dependencies (conditions and co-variance) between the considerations.
Allow us to dig down one degree in every of the three views.
Federated Semantics
Sure, this feels like knowledge fashions, however right here in 2023 we don’t do UML that a lot anymore. Simpler and semi-intelligent options are at hand. So, don’t shrink back, but.

Accountability
Having established what (semantics) you might be speaking about it’s time to examine the assorted facets of reliability of knowledge.
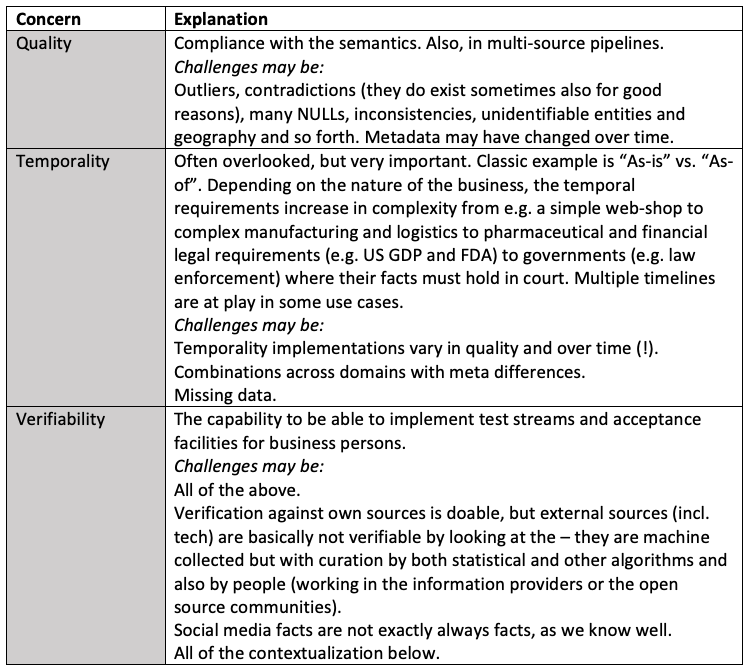
Contextualization
These are last validations to find out the enterprise affect, which may be delivered.

Causes and Prices of Information Debt
I’ve tried to level you to the problems to be careful for within the little evaluation mannequin above. Different folks have written superb and deep posts about knowledge debt. For instance:
There are many causes (excuses) for leaving one thing undone – till hopefully later.
John Ladley, who’s a really educated particular person with a deep understanding of the affect of knowledge on enterprise outcomes, provides his greatest recommendation within the put up referenced above. Take pleasure in his “knowledge debt quadrant” within the put up!
However knowledge debt comes at a price. John Ladley dangers his neck at a doable 10% affect on the annual IT prices spent on coping with knowledge debt gadgets.
That’s simply the tangible growth prices. I preserve that there may additionally be worse uncomfortable side effects akin to buyer dissatisfaction, misplaced income, too low earnings, and many others.
One among my favourite horror tales is a few multinational B2C firm that needed to implement a brand new gross sales reporting scheme. They constructed it accumulating knowledge from plenty of ERP programs working in numerous international locations – solely to find that the consolidated knowledge base was lacking product class hierarchy info in additional than 50 % of the gross sales report strains! That delayed the challenge with a number of months, the place younger, robust, controllers took turns visiting the completely different daughter firms … If they’d recognized that beforehand, the challenge would most likely have seemed completely different.
Automation to the Rescue?
Principally, there are two sorts of automated assist doable:
- Data primarily based on ready semantics and/or acquired metadata from APIs from tech or open-source info suppliers, or
- Statistical (guessing) strategies (ML) supplemented with entity recognition all primarily based on knowledge at hand
The seller and open-source alternatives develop rapidly, so the next are simply my bets as of the time of writing. I’ve tried to price the attractiveness (0 to 10) of the 2 approaches throughout the considerations:

In fact, these scores may be debated. Nonetheless, I believe the advice is evident: Wherever you may, you need to search for semantics-based enter. The enterprise affect will enhance, and the reliability shall be increased.
The alternatives are definitely there. The instruments differ wildly throughout completely different platform classes – knowledge cloth, knowledge catalogs, knowledge mesh, ETL, semantic media, semantic layers, and all the remaining. Watch out on the market, however do reap the benefits of semantic applied sciences!
2023 Alternatives
Contemporary out right here in 2023 is a brand new ebook by Andrew Iliadis of Temple College: “Semantic Media – Mapping That means on the Web.” He comes from the data science facet of the home and has a pleasant, pragmatic, and utility-oriented method to what we are able to study from semantic media.
There are many these in the present day: Google, Wikidata, Amazon, Fb, IBM, eBay, Apple, Microsoft, and extra (talked about within the order of look within the ebook). Nearly all of them are graphs (semantic graphs and some property graphs). A few of them are in “pre-GA,” some are open supply, however most are proprietary. Word that regardless of the massive information graphs utilized by Google and the others are constructed from very massive datasets, there’s some curation (automated and guide) utilized, and there are a number of tales about incorrect search engine outcomes. In actual fact, serps are considerably yesterday. Immediately it’s about offering info – in a one-stop purchasing method.
On this area you discover information bases and ditto graphs, information panels and, not least, APIs. All are potential sources of data having structured codecs (semantic metadata). And, sure, it’s closely influenced by RDF/OWL and associated semantic applied sciences. It is a wealthy pond so that you can fish in in 2023! Preserve me up to date once you get an enormous catch!
Andrew’s ebook will not be a how-to textbook. However I’m positive you’ll discover some helpful instructions. The primary three beneath are impressed by his ebook, and they’re accompanied by an instance of an business sector semantic normal and the final two are examples of how you can get semantics into property graphs:
So, what all of it boils right down to is that it’s certainly doable to do one thing to deliver down knowledge debt when growing analytics pipelines, and many others. You possibly can herald a few of this new pondering that can assist you progress quicker and in addition extra safely:
- The mixture of contextualization, federated semantics, and accountability dictates that you need to (and will) construct a information graph in 2023
- You are able to do that by
- Leveraging APIs to semantic media akin to Google, Apple, Microsoft, and many others., and/orTake benefit of open semantic sources akin to
- WikidataIndustry-standard ontologiesInternational and nationwide normal ontologiesOther roughly open sources akin to Opencorporates and lots of extra
- Constructing it in property graph know-how, which has a neater studying curve than RDF
- Leveraging APIs to semantic media akin to Google, Apple, Microsoft, and many others., and/orTake benefit of open semantic sources akin to
- You might use your individual information graph as an necessary a part of the information contract with the enterprise (make necessities machine-readable, or you may maintain easy textfiles in e.g. PlantUML idea syntax)
- You should utilize your information graph to make completeness checks in addition to search for accountability options, lacking info, (lack of) temporality info, and so forth
- You should utilize a graph prototype as a take a look at and verification platform for the businesspeople
Studying graph database is of the essence. That is it – go for it – I’m actually enthusiastic about this palette of 2023 alternatives! Disruption? Sure, and one – fixing actual issues.
Preserve me posted!
[ad_2]