
[ad_1]
Learn Part1 of This Right here
Okay .
What do now we have : nodes , layers and the online and the feed ahead features .
So what does that imply within the spectrum of “an issue” ?
It signifies that if our drawback has parameters / options we are able to ship them in by way of the enter layer and get a forecast or prediction from the community .
Now the issue is the community is guessing as a result of its at a random state.
What do we have to do to show it ? We have to get samples with a identified right reply , throw their options within the enter layer , calculate the community , and evaluate the right reply with the networks prediction.
Yeah no sh*t Lorenso we all know that , so , every weight on the community is accountable for the prediction we get , proper or incorrect .
When that prediction is incorrect we need to notice how incorrect we’re and transfer in the wrong way . I will not contact on the derivatives and why we use the chain rule and all that , if you’re i’ve one other additionally very severe blogpost about that right here
So , to the duty , what you hear on a regular basis is now we have this loss operate and we calculate the error and we again propagate the error blablalba . What should we do in code thought ?
Let us take a look at the node construction first .
class snn_node{ public: double weights[]; double weight_adjustments[]; double bias,bias_adjustment; double error; double output; snn_node(void){reset();} ~snn_node(void){reset();} void reset(){ ArrayFree(weights); ArrayFree(weight_adjustments); bias=0.0; bias_adjustment=0.0; error=0.0; output=0.0; } void setup(int nodes_of_previous_layer, bool randomize_weights=true, double weights_min=-1.0, double weights_max=1.0){ ArrayResize(weights,nodes_of_previous_layer,0); ArrayResize(weight_adjustments,nodes_of_previous_layer,0); ArrayFill(weight_adjustments,0,nodes_of_previous_layer,0.0); if(randomize_weights){ init_weights(weights_min,weights_max); }else{ ArrayFill(weights,0,nodes_of_previous_layer,1.0); bias=1.0; } } void init_weights(double min,double max){ double vary=max-min; for(int i=0;i<ArraySize(weights);i++){ weights[i]=(((double)MathRand())/32767.0)*vary+min; } bias=(((double)MathRand())/32767.0)*vary+min; } void feed_forward(snn_node &previous_layer_nodes[]){ output=0.0; error=0.0; for(int i=0;i<ArraySize(previous_layer_nodes);i++){ output+=previous_layer_nodes[i].output*weights[i]; } output+=bias; output=activationSigmoid(output); } void reset_weight_adjustments(){ for(int i=0;i<ArraySize(weight_adjustments);i++){ weight_adjustments[i]=0.0; } bias_adjustment=0.0; } };
We’ll assemble a again propagation operate.
On the time this operate is known as for this node , it means , now we have summed up the error from the nodes of the subsequent layer that this node is accountable for .
However , the error produced is by the output that has gone by the activation operate of this node . Proper ? So what do we have to do ? we should get the slope of that or the impact the node has on the community , how ? with the … spinoff (you hate that phrase by now most likely).
So , what will we do first ? we multiply the error now we have obtained by the spinoff of the activation operate . Straightforward , and , what do we have to obtain for this operate ?
2 issues :
- Whether or not or not we should always ship the error to the earlier layer (in case that is layer 1 and the layer earlier than it’s the enter layer , and the enter layer doesn’t “be taught”)
- the array of the nodes of the earlier layer.
okay let’s construct it:
void back_propagation(bool propagate_error, snn_node &previous_layer_nodes[]){ error*=derivativeSigmoid(output); }
See the error is what we had obtained from the proper aspect of this layer for this node and we simply multiply it by the spinoff of the sigmoid .
Cool .
Now in the event you’ve learn the opposite submit you may have a recent view on the derivatives for this course of and why they’re what they’re , however let’s briefly point out it once more :
For a node now we have weights which are multiplied by the output values of the nodes of the earlier layer and go right into a field that sums them up .
So every weight’s have an effect on on the sum ,and on the error by extention, relies on the output of the node of the earlier layer it connects to (that’s how we’re going to calculate the adjustment wanted for this weight) . It makes whole sense proper ?
The sum at this node obtained some values , and one weight impacts the sum by “output of the node it connects to” magnitude .
How a lot did this weight have an effect on the sum that goes into the activation is proportionally equal to how a lot this weight will change based mostly on the error this node produced . Proper ?
Look how easy that’s , keep in mind we’re storing the burden changes within the equal array (the community shouldn’t be studying but)
void back_propagation(bool propagate_error, snn_node &previous_layer_nodes[]){ error*=derivativeSigmoid(output); for(int i=0;i<ArraySize(weights);i++){ weight_adjustments[i]+=error*previous_layer_nodes[i].output; } bias_adjustment+=error; }
Do not be confused by the very fact we’re including , we’re simply accumulating the overall adjustment that we’re going to apply to this weight on the finish of the batch (and the bias too).
Magical proper ? we took the error , we unpacked it and now we all know how a lot the burden should change for this correction.
Nice , and now take a look at how easy the opposite half is (the again propagation , i.e. the spreading the error backwards)
How “accountable” is a node of the earlier layer for the error on this layer ?
Easy , it’s Weight quantity accountable , you do the very same factor , virtually , to ship the error again to the nodes of the earlier layer :
void back_propagation(bool propagate_error, snn_node &previous_layer_nodes[]){ error*=derivativeSigmoid(output); if(propagate_error){ for(int i=0;i<ArraySize(previous_layer_nodes);i++){ previous_layer_nodes[i].error+=weights[i]*error; } } for(int i=0;i<ArraySize(weights);i++){ weight_adjustments[i]+=error*previous_layer_nodes[i].output; } bias_adjustment+=error; }
That is it , all that math and the equations results in that little operate above .
Superior , now , you’ll need to name this operate from a layer too so let’s add it there as effectively ,
don’t worry about the entire construction of the node , the complete supply code embody is connected on the backside of this weblog .
So the layer again prop operate , what do we have to ship ? whether or not or not we should backpropagate to the earlier layer ,and, the earlier layer.
Then we loop within the nodes and name the again propagation for every one in all them :
that is for the layer construction
void back_propagation(bool propagate_error, snn_layer &previous_layer){ for(int i=0;i<ArraySize(nodes);i++){ nodes[i].back_propagation(propagate_error,previous_layer.nodes); } }
Nice , and , let’s eradicate one other situation you’re most likely questioning about proper about now .
How will we get the error for the output layer , do not we’d like a operate for that ?
Sure , and here is how easy that’s too :
We create a operate to calculate the error on the output nodes of the community .
We give it a definite title to not name it accidentally
And what will we ship in there ? the right solutions of the pattern !
That is it . And what will we count on it to return to us ? The loss operate worth .
And that is the place all of the quadratics and the and hellingers and the itakura-saiko and cross-entropy buzz phrases are coming in .
That is the operate you place them at .
For this instance we use the best one the quadratic loss operate .
this operate goes within the layer construction as effectively
double output_layer_calculate_loss(double &correct_outputs[]){ double loss=0.0; for(int i=0;i<ArraySize(correct_outputs);i++){ loss+=MathPow((nodes[i].output-correct_outputs[i]),2.0); } loss/=2.0; for(int i=0;i<ArraySize(nodes);i++){ nodes[i].error=nodes[i].output-correct_outputs[i]; } return(loss); }
Glorious , now let’s pause and assume .
We’re lacking 2 issues , 1 how the online construction handles the error and backpropagates , 2 how the community learns.
espresso break .

Let’s draw some stuffs
The community will obtain a pattern for which now we have a identified consequence and push the “parameters/options/inputs” of this pattern into the enter layer
triggering an avalanche of calculations :

The community will reply with forecast f (which within the academian lingo is “a vector” , in our lingo its an array that may be of any size.
We then have one other array which is the right values for this pattern let’s name it C (a vector of identified outcomes of their lingo)
And what we should do now could be evaluate C to f and :
- tally how incorrect the community is for this pattern right into a normal whole loss utilizing any of the equations the tutors have been stuffing our face with with out explaining the place they go ( 🤣 ,jk )
- then measure how incorrect every node of our output is
- then ship these errors again all the best way to layer1 and log weight changes for the community
Let’s professionally draw this :
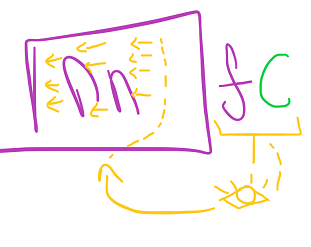
Good , what’s the “output” ? Its the final layer of the community , and what’s the array f ? its the array of the nodes of the final layer of the community.
So , again to the online stucture ,
we’ll add an integer samples_calculated that can rely what number of samples now we have “seen” with the orange eye proper there , and , a double total_loss that can measure how incorrect this “batch” (theres one other buzzword that popped up out of nowhere , on the proper time although) is in whole utilizing the magical equations smarter than us folks have supplied.
However wait , we wrote these equations on the calculate loss operate . Aha So what’s going to we do within the web construction ?
We’ll enhance samples calculated , and name the final layers calculate loss operate . And that’s it !
void calculate_loss(double &sample_correct_outputs[]){ samples_calculated++; total_loss+=layers[ArraySize(layers)-1].output_layer_calculate_loss(sample_correct_outputs); }
Straightforward proper ? However wait a minute , the output_layer_blabla factor additionally ready the error on the nodes of the output layer for us , proper ?
Sure , that signifies that we are able to now name again propagation for your complete community , however , let’s separate the operate for comfort.
void back_propagation(){ for(int i=ArraySize(layers)-1;i>=1;i--){ layers[i].back_propagation(((bool)(i>1)),layers[i-1]); } }
Thats it , we begin from the final layer all the best way until layer 1 , and , we keep in mind to ship a “false” if the layer is 1 as a result of we can’t again propagate the error to layer 0 (which is the enter layer)
Magic , virtually finished . By the point you name back_propagation() on the web construction your community is able to “be taught” .
So let’s do it
Take a look at how easy that is , once you see it and evaluate it to the six boards stuffed with equations on the mit video you first watched you will not imagine your ears .
We return to the node construction , okay ?
Let’s assume all of the again propagations have accomplished .
We have to do what ?
Add the array weight_adjustments (that has been accumulating corrections) to the array of the weights . and do this for the bias too.
We have to ship what although ? a studying charge
void alter(double learning_rate){ for(int i=0;i<ArraySize(weights);i++){ weights[i]-=learning_rate*weight_adjustments[i]; } bias-=learning_rate*bias_adjustment; reset_weight_adjustments(); }
6 strains of code , and the sixth line we do not neglect to name the adjustment reset , and that is it , this node “discovered” .
How concerning the layer ?
void alter(double learning_rate){ for(int i=0;i<ArraySize(nodes);i++){ nodes[i].alter(learning_rate); } }
Identical factor , we ship the educational charge , it goes into its nodes and calls alter.
How about your complete community ?
void alter(double learning_rate){ for(int i=1;i<ArraySize(layers);i++){ layers[i].alter(learning_rate); } }
Identical factor , studying charge in , calls all layers (apart from 0) and adjusts nodes
That is it , you now have a working easy neural web library .
However wait , let’s do a pair extra dribbles .
Would not it’s fantastic if the community deccelerated its studying charge because it received higher and higher ? sure
can we offer the means to the coder (you) to calculate that ?
sure. We will present a calculation of the max doable loss per pattern , and , the present loss per pattern .
We plug these within the web construction :
double get_max_loss_per_sample(){ double max_loss_per_sample=((double)ArraySize(layers[ArraySize(layers)-1].nodes))/2.0; return(max_loss_per_sample); } double get_current_loss_per_sample(){ double current_loss_per_sample=total_loss/((double)samples_calculated); return(current_loss_per_sample); } void reset_loss(){ total_loss=0.0; samples_calculated=0; }
We additionally add a reset loss operate for once we begin a brand new batch . However wait what’s that , the max loss is the nodes of the final layer divided by 2 ?
Sure for the quadratic loss operate we’re utilizing .
Let’s have a look at the equation actual fast , that is the loss per pattern :
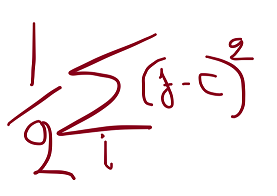
That is you are taking the prediction of the community at every node i and also you subtract the right reply for that node , you sq. the distinction and also you sum this for all of the output nodes , then divide by 2.
What’s the most this equation can spit out per node if all of the nodes are incorrect ? (and bearing in mind the sigmoid operate outputs from 0.0 to 1.0) , 1 , -1 squared and 1 squared equal 1 . So the sum of the output nodes by 2 , that’s how we received there . Should you use totally different loss features you’ll need to alter that .
Cool , let’s examine how would we set a web utilizing this library , for the xor drawback at that.
Let’s deploy this :
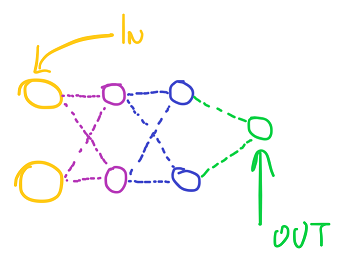
snn_net web; web.add_layer().setup(2); web.add_layer().setup(2,2); web.add_layer().setup(2,2); web.add_layer().setup(1,2);
Straightforward . and , how will we do the coaching thingy ?
Let’s do it for the Xor drawback , we’d like 2 options and 1 output
double options[],outcomes[]; ArrayResize(options,2,0); ArrayResize(outcomes,1,0); for(int i=0;i<1000;i++) { int r=MathRand(); if(r>16000){options[0]=1.0;}else{options[0]=0.0;} r=MathRand(); if(r>16000){options[1]=1.0;}else{options[1]=0.0;} if(options[0]!=options[1]){outcomes[0]=1.0;}else{outcomes[0]=0.0;} web.feed_forward(options); web.calculate_loss(outcomes); web.back_propagation(); } web.alter(0.1); web.reset_loss();
So what did we do ? we skilled on a batch of 1000 samples with a identified reply :
- We randomize the primary function 0 or 1 , then the second , we retailer these 2 within the options array .
- Then we calculate the right consequence and put it within the outcomes array (which has measurement of 1)
- then we name (per pattern) the feed ahead of the online by dumping within the options of this pattern
- then we name the loss calculation and we ship within the right outcomes array (for this pattern , the outcomes array has the identical measurement because the nodes of the final layer)
- then we again propagate and accumulate changes for the 1000 samples .
- Exiting the loop we carry out the changes collected with a 0.1 studying charge
- after which we reset the loss (whole loss stat and samples calculated)
Superior , and , how will we alter the educational charge based mostly on the loss ?
double max_loss=web.get_max_loss_per_sample(); double cur_loss=web.get_current_loss_per_sample(); double a=(cur_loss/max_loss)*0.1; web.alter(a); web.reset_loss();
We get the max loss doable per pattern , and , the present loss per pattern .
We divide the present loss by the max loss , so if now we have the utmost doable loss per pattern this returns 1.
then the results of this division is multiplied by a base studying charge (0.1 in our instance)
after which we name the alter operate with that worth .
So if the loss by the max loss per pattern returns 0.1 we’ll get a studying charge of 0.1*0.1 = > 0.01 , slowing down as we method the answer , as your ea reaches holy grail territory 😋
That’s it , i am attaching the supply code and the instance of a xor community .


[ad_2]