
[ad_1]
XOR Gate instance neural web in mql5 , so simple as doable 🍺
I will assume what the XOR gate “downside” is .
A fast refreshing professional schematic :
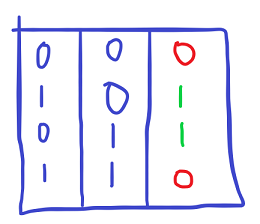
The primary 2 columns are the two inputs and the third column is the anticipated consequence from that operation . So 0v0=0 1v0=1 0v1=1 1v1=0
It’s a neat little job to let a nn have a go at and its easy sufficient to permit discovery of our errors , in code or within the interpretation of the maths.
That is how the ensuing web will appear like
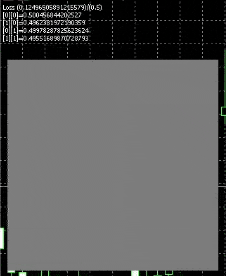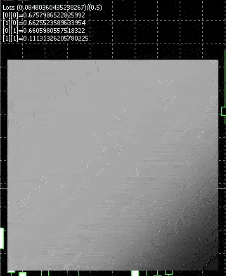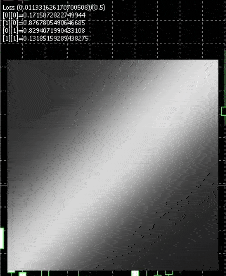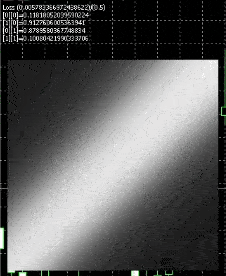
White represents nodes firing , we have now a sq. show for testing , and , we feed in inputs 0 to 1 for each axis , so it fires when the x axis approaches 1 or the y axis approaches 1.
What we’ll do right here , we are going to create 3 easy constructions :
- A neural node
- A neural layer with nodes
- A neural web with layers with nodes
Sco
I recall among the questions i had beginning out so i am going to share the solutions (that is probably not 100%) right here :
- “Do i must divide the load changes (to study) by the variety of batches?” – No
- “A node connects ahead to a number of different nodes , do i must common out the error it receives?” – No
- “Why is the loss perform i am utilizing to backpropagate the error completely different than the loss perform i am utilizing to calculate the price or the how mistaken the general web is ?” – Its not completely different , the loss you ship per node for again propagation is the by-product of the loss perform you employ to calculate the “price”
- “Why do i ship a -= within the weight changes and never a +=”? – it has to do with math and that the derivatives are the speed of the present heading of the general community or one thing , i used to be caught on this straightforward factor for a very long time however fortunately its only a signal change . I haven’t got a correct rationalization for that.
- “Do i must calculate the error from the loss perform per output node individually ? “ – sure every node has its personal error (which is the by-product of the loss perform)
- “Do i again propagate with the outdated weights or the adjusted weights ?” – the outdated weights
To the duty !
A.The nodes :
i will not bore you with the why’s and idea , truly the net is filled with that .What i recall from the times i began -trying- to study that’s : eager for a f********ng easy supply code (on any language) that really defined what was happening and never simply reciting math or utilizing a python library.
So :
what kinds of nodes are there ?
- An enter node
- A node of a hidden or dense layer
To simplify
- A node that doesn’t regulate its weights nor does it obtain error (enter)
- A node that adjusts its weights and receives error (from ahead layers or the consequence we search itself)
How will we deploy nodes right here ?

Take into account the little ball with the f on it the node of which the category we’ll sort out proper now.
f is the activation perform additionally which spits out an output (out)
Summer time is the summation of all of the weights multiplied by every node of the earlier layer and naturally the bias.
While you draw schematics in your web at first draw the summers too , it helps with derivatives .
The activation perform we’ll use is , what else , the sigmoid .
So let’s blurt this perform out :
double activationSigmoid(double x){ return(1/(1+MathExp(-1.0*x))); }
and naturally the dreaded by-product :
double derivativeSigmoid(double activation_value){ return(activation_value*(1-activation_value)); }
Okay , prepared ? class snn_node (easy neural web)
What’s the very first thing we’d like ? the weights
Effectively what number of weights ? it is determined by every earlier layer , meaning an array !
Additionally we’ll want a bias and a few fundamental stuff
class snn_node{ public: double weights[]; double bias; snn_node(void){reset();} ~snn_node(void){reset();} void reset(){ ArrayFree(weights); bias=0.0; } };
Okay , however will not we’d like a strategy to set this up ? sure !
What do we have to ship to the setup perform ? the variety of nodes the earlier layer has . Why ? as a result of we may have one weight for every
node of the earlier layer.
so our setup will appear like this :
void setup(int nodes_of_previous_layer){ ArrayResize(weights,nodes_of_previous_layer,0); }
At this level you remembered that you have to randomize the weights at first . Effectively we will create a neat little perform for that :
void init_weights(double min,double max){ double vary=max-min; for(int i=0;i<ArraySize(weights);i++){ weights[i]=(((double)MathRand())/32767.0)*vary+min; } bias=(((double)MathRand())/32767.0)*vary+min; }
(we additionally initialize the bias)
So what occurred right here ?
- We obtain a minimal and most worth that the random weights will need to have
- we then calculate the vary of the weights by subtracting the minimal from the utmost (ex min=-1 max=1 vary=2)
- we then cycle within the # of weights -how do we all know the # of weights? the perform will likely be within the node class- we ask mql5 for a random quantity from 0 to 32767
- we flip it to a double sort
- we divide it by the max vary of the random perform (32767.0) this manner we get a worth from 0 to 1
- then we multiply that 0 to 1 worth with the vary we would like our weights to have
- and eventually we add the minimal
- Fast instance (0.5)*vary+min=(0.5)*2-1.0=0.0 , 0.5 that was in the course of 0 to 1.0 is in the course of -1.0 to 1.0 , perfection.
Wait , can we embody this perform within the class and now have it linked to the setup perform ? sure
void setup(int nodes_of_previous_layer, bool randomize_weights=true, double weights_min=-1.0, double weights_max=1.0){ ArrayResize(weights,nodes_of_previous_layer,0); if(randomize_weights){ init_weights(weights_min,weights_max); }else{ ArrayFill(weights,0,nodes_of_previous_layer,1.0); bias=1.0; } }
So now the node setup has the preliminary randomizer on by default with default weights vary -1.0 to 1.0 , if the consumer (coder) desires to alter it they may sort it in.
Now let’s suppose , we have now the node and the weights to the earlier layer , what else do we’d like ?
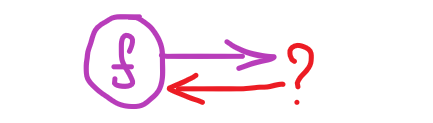
That is proper what can we do after we obtain an error , and the place will we retailer it and what is going to we course of first ?
effectively , let’s chill out

good , right here is the order :
We will likely be calculating the error on the output (rightmost finish) , then per layer we are going to ship the error again to every node of the earlier layer , in sequence , so as . So our little node might want to retailer the error it receives someplace , why ? as a result of till the layer that’s at present backpropagating finishes we have to hold summing up the error that the node is liable for .
Complicated ? okay , once more , you’re promoting an algorithm , you ship your supply to three patrons . When the primary purchaser solutions you wont instantly settle for or decline , you may watch for the opposite 2 after which its your flip.
Equally however by no means a node is liable for the nodes of the subsequent layer it hyperlinks out to .
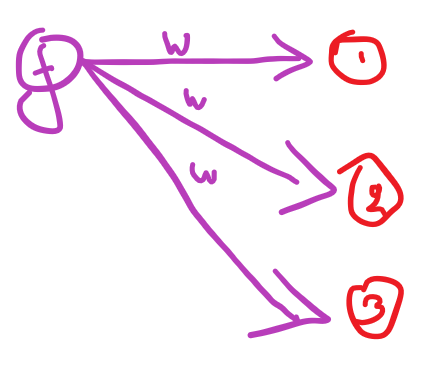
The node f is liable for errors on the subsequent layer’s node 1 node 2 and node 3 so after they backpropagate (after they level the finger at node f saying its it is fault) node f must know the way a lot of a “unhealthy boy” it’s . What does that depend upon ? the weights 🙂 Node f has a partial accountability for the errors every of the nodes of the subsequent layer do , and the community’s errors as an entire too.
Bought it ? nice , all that simply so as to add a variable to the category 😂
And we’ll additionally add an output variable as a result of the next layers might want to learn from this node too.
double error; double output;
And proper about right here we arrive at thrilling second numero uno . The calculation of the node or the “feed ahead” .
What can we do on the feed ahead , come on , that is the simple sh*t .
We take the node outputs of the earlier layer multiplying every one by the load , on the finish of that sum we slap on the bias after which we move that by means of the activation perform , and we have now the output of the node .
We additionally reset the error (=0.0) , why ? as a result of this variable will maintain and switch , or slightly , infect the nodes with the error worth for one pattern solely .(for every pattern)
and here is the way it seems to be :
void feed_forward(snn_node &previous_layer_nodes[]){ output=0.0; error=0.0; for(int i=0;i<ArraySize(previous_layer_nodes);i++){ output+=previous_layer_nodes[i].output*weights[i]; } output+=bias; output=activationSigmoid(output); }
Self explanatory proper ?
to calculate this node :
- we name the feed_forward
- we ship in an array with the nodes of the earlier layer
- we set the output and the error to 0.0
- we loop within the whole nodes of the earlier layer – which is identical quantity because the weights of this node
- we add the earlier node’s output worth x the load , they’ve the identical [i] index , duh
- out of the loop we add the bias worth
- then we move it by means of the activation perform we constructed earlier
and that node is baked prepared for use by the subsequent layer
Superior

Onwards
Now , time to face the laborious stuff . Sooner or later we all know we’ll must deal with the dreaded backpropagation .
What does that imply ? let’s suppose .
The backpropagation will calculate one thing proper ? and that one thing will likely be used to regulate the weights of the nodes .
However we can’t regulate the weights instantly so we’d like a …. sure one other array for the load changes .
We are going to dump all of the modifications the weights must endure in that array (so similar measurement because the weights) , and
then after we need to make the community “study” we’ll use that assortment of changes .
Is that this the one method ? no , however , it helps hold issues easy and extra comprehensible at first .
So , let’s add the load changes array , we’ll name it weight changes 😛
Do not forget , we should measurement it on setup of the node together with the weights and initialize it to 0.0 !
We can even want to regulate the bias , so , we additionally add a bias adjustment worth
double weight_adjustments[]; double bias_adjustment; void reset_weight_adjustments(){ for(int i=0;i<ArraySize(weight_adjustments);i++){ weight_adjustments[i]=0.0; } bias_adjustment=0.0; }
and since we’re good we added a reset changes perform for comfort.
Cool now its time to deploy the layers first after which we are going to come again for the backprop.
Let’s take a break , and take a look at the issues we have now up to now …

superb proper ? you’re one backprop perform ,one layer construction and one community construction away out of your neural web library !
so …
B.The Layers
For the layers we have to remember that there will likely be 2 varieties . The enter layer and the hidden layers (and output layer) , the non enter layers in different phrases , or the layers that study and one layer that doesn’t study . So :
what does a layer have ? nodes
class snn_layer{ public: snn_node nodes[]; };
pfft , straightforward sh*t…
What else do we’d like ? to setup the layer , and , the fundamental stuff , reset , constructor destructor and so on.
And for the setup we may have two variations . One with simply the variety of nodes for the layer , for enter layers and one with the variety of nodes , the variety of nodes of the earlier layer and another choices . We are going to primarily be capable to setup the layer and its nodes immediately .
That is what we would like , and right here is the way it seems :
class snn_layer{ public: snn_node nodes[]; snn_layer(void){reset();} ~snn_layer(void){reset();} void reset(){ ArrayFree(nodes); } void setup(int nodes_total){ ArrayResize(nodes,nodes_total,0); } void setup(int nodes_total, int previous_layer_nodes_total, bool randomize_weights=true, double weights_min=-1.0, double weights_max=1.0){ ArrayResize(nodes,nodes_total,0); for(int i=0;i<ArraySize(nodes);i++){ nodes[i].setup(previous_layer_nodes_total,randomize_weights,weights_min,weights_max); } } };
The primary setup simply resizes the nodes array , so the layer has nodes , and its most likely an enter layer.
the second setup receives the variety of nodes to deploy , and in addition units up the nodes primarily based on the nodes # of the earlier layer (for the weights of every node) and , some elective weight initialization choices . The second setup primarily prepares the layer totally for operation .
Glorious , what else ? how will we be calling the calculation (the feed ahead) of every node ?
We may have a perform on the layer too which in flip will name all its nodes to be calculated . neat
What is going to that perform must obtain although ? hmm , what do the nodes of this layer depend upon for his or her calculation ?
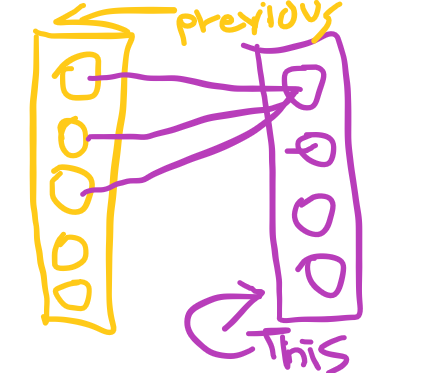
the weights and the earlier layer , aha! so the “feed ahead” name of this layer ought to obtain the earlier layer :
void feed_forward(snn_layer &previous_layer){ for(int i=0;i<ArraySize(nodes);i++){ nodes[i].feed_forward(previous_layer.nodes); } }
that is it , that is the perform :
- we ship the earlier layer in
- we loop to the nodes of this layer
- for every node we name it is feed ahead and we ship the what ? the array of nodes of the earlier layer
- helpful
However wait … what in regards to the enter layer ? Ah , the enter layer has no calculation however we simply must ship within the values proper ?
Let’s create a perform for that too :
void fill_as_input_layer(double &inputs[]){ for(int i=0;i<ArraySize(nodes);i++){ nodes[i].output=inputs[i]; } }
?…what? that is it ? yep . You ship the inputs array of a pattern and it fills the enter layer output values , of every node . We give it a definite title in order that we don’t name the mistaken perform accidentally , however kind of that is it with the feed ahead.
Let’s go for the online construction after which do the laborious stuff .
C.The Community
what does the networ… layers
class snn_net{ public: snn_layer layers[]; snn_net(void){reset();} ~snn_net(void){reset();} void reset(){ ArrayFree(layers); } };
so , an array of layers , and the fundamental stuff , superior . Will we’d like a setup perform ? mmmmm nope , we will add a layer addition perform
that returns a pointer to the brand new layer and we will straight play with the returned pointer .(i.e. set the brand new layer up proper then and there utilizing the layer features) :
snn_layer* add_layer(){
int ns=ArraySize(layers)+1;
ArrayResize(layers,ns,0);
return(GetPointer(layers[ns-1]));
}
Now after we name : web.add_layer() we’ll be capable to hold typing and name the setup perform straight for that layer.
Nice , and naturally , the feed ahead perform , proper ? what is going to that want ?
Mistaken , it wants the array of inputs for the pattern it’ll calculate , and here is the way it seems to be :
void feed_forward(double &inputs[]){ layers[0].fill_as_input_layer(inputs); for(int i=1;i<ArraySize(layers);i++){ layers[i].feed_forward(layers[i-1]); } }
So what does it do ? :
- obtain a listing of enter values
- then these go within the first layer (fill as enter layer)
- then we loop from layer 1 to the final layer
- and we name the feed ahead for every layer
- and we ship the layer i-1 to the feed ahead perform (every earlier layer)
And that’s it , the feed ahead half is full .
How about we additionally give it a perform that returns the results of a particular output node ?
sure . What’s an output node ? a node on the final layer !
so the perform will appear like this :
double get_output(int ix){ return(layers[ArraySize(layers)-1].nodes[ix].output); }
go to the final layer , and return the output worth of that node , easy proper ?
Okay ,now , take an enormous break as a result of we’ll dive to
the toughest a part of all of it …
Prepared ? wonderful


[ad_2]