
[ad_1]
Machine Studying (ML) is a big subset of synthetic intelligence that research strategies for constructing learning-capable algorithms. (Wikipedia Definition)
It’s also possible to discover such a definition. Machine studying is a department of AI that explores strategies that permit computer systems to enhance their efficiency primarily based on expertise.
The primary self-learning algorithm-based program was developed by Arthur Samuel in 1952 and was designed to play checkers. Samuel additionally gave the primary definition of the time period “machine studying”: it’s “the sphere of analysis within the growth of machines that aren’t preprogrammed.”
In 1957, the primary neural community mannequin was proposed that implements machine studying algorithms much like fashionable ones. Quite a lot of machine studying techniques are at the moment being developed to be used in future applied sciences such because the Web of Issues, the Industrial Web of Issues, the idea of a “good” metropolis, the creation of uncrewed automobiles, and plenty of others.

The next details proof the truth that nice hopes are actually pinned on machine studying: Google believes that quickly its merchandise “will now not be the results of conventional programming – they are going to be primarily based on machine studying”; New merchandise like Apple’s Siri, Fb’s M, and Amazon’s Echo have been constructed utilizing machine studying. In 1957, the primary neural community mannequin was proposed that implements machine studying algorithms much like fashionable ones. Quite a lot of machine studying techniques are at the moment being developed to be used in future applied sciences such because the Web of Issues, the Industrial Web of Issues, the idea of a “good” metropolis, the creation of uncrewed automobiles, and plenty of others.
Now that we’ve found out what machine studying is let’s have a look at tips on how to construct a machine studying system in order that it really works successfully for a selected enterprise’s particular objectives.
- What’s a machine studying pipeline?
- Mannequin preparation course of
- Machine studying pipeline in manufacturing
- Machine studying mannequin retraining pipeline
- Instruments for machine studying pipeline creation
- Why is the machine studying pipeline vital?
What’s a machine studying pipeline?
A machine studying pipeline (or system) is a technical infrastructure used to handle and automate machine studying processes. The logic of constructing a system and selecting what is important for this relies solely on machine studying instruments—pipeline administration engineers for coaching, mannequin alignment, and administration throughout manufacturing.
A machine studying mannequin is a consequence obtained by coaching a machine algorithm utilizing information. After coaching is full, the mannequin produces an output when enter information is entered into it. For instance, a forecasting algorithm creates a forecasting mannequin. Then, when information is entered into the predictive mannequin, it points a forecast primarily based on the information used to coach the mannequin.
There’s a clear distinction between coaching and working machine studying fashions in manufacturing. However, earlier than we have a look at how machine studying works in a manufacturing surroundings, let’s first have a look at the steps concerned in getting ready a mannequin.
Mannequin preparation course of
When creating a mannequin, information engineers work in some growth surroundings particularly designed for machine studying, equivalent to Python, R, and many others. They usually can prepare and take a look at the fashions in the identical “sandboxed” surroundings whereas writing comparatively little code. It’s wonderful for fast-to-market interactive prototypes.
The machine studying mannequin preparation course of consists of 6 steps. This construction represents the best approach to course of information via machine studying.
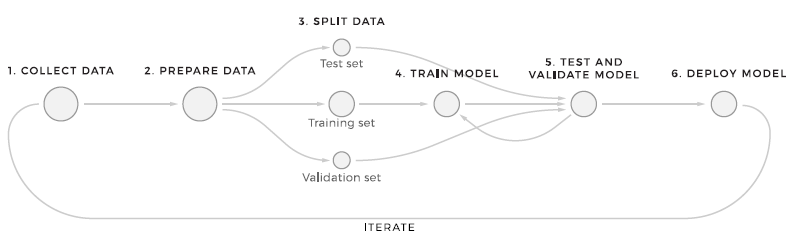
- Gathering the required information. The very first thing that any ML workflow begins with is sending incoming information to the shop. No transformations are utilized to the information at this level, which lets you maintain the unique information set unchanged.
NoSQL databases are appropriate for storing giant quantities of quickly altering structured and/or unstructured information as a result of they don’t comprise schemas. Additionally they supply distributed, scalable, replicated information storage. - Knowledge preparation. As quickly as the information enters the system, the distributed pipeline appears to be like for variations in format, traits, information correctness, and which information is lacking and corrupted and corrects any anomalies. This step additionally contains the characteristic growth course of. There are three predominant phases within the operate pipeline: extract, remodel, and choose.

Making ready the information is the toughest a part of an ML mission. Implementing the proper design patterns is important. Additionally, don’t forget that they’re transformed a number of occasions. That is typically carried out manually, specifically, formatting, cleansing, labeling, and enriching the information in order that the information high quality for future fashions is suitable. After getting ready the information, information scientists start to design capabilities. Capabilities are information values that the mannequin will use in each coaching and manufacturing.
Every characteristic set is assigned a novel identifier to make sure consistency of performance - Knowledge separation. At this stage, it’s mandatory to separate the information, to begin with, to show the mannequin and later verify the way it works with new information. A machine studying system’s main objective is to make use of an correct mannequin primarily based on the standard of predicting patterns on information that it has not beforehand educated on. There are lots of methods for this, equivalent to utilizing normal ratios, sequentially, or randomly.
- Mannequin Studying: Right here, in flip, it’s price utilizing a subset of the information in order that the machine studying algorithm acknowledges particular patterns. The mannequin coaching pipeline works offline and may be triggered by time and by the occasion. It consists of a library of coaching mannequin algorithms (linear regression, k-means, determination bushes, and many others.). The coaching of the mannequin ought to be carried out, making an allowance for the resistance to errors.
- Testing and Validation: Evaluating mannequin efficiency entails utilizing a take a look at subset of the information to achieve a deeper understanding of how correct the prediction is. By evaluating outcomes between exams, the mannequin may be tuned/modified /educated on completely different information. The coaching and analysis steps are repeated a number of occasions till the mannequin reaches a suitable share of right predictions.
- Deployment: As soon as the chosen mannequin is created, it’s normally deployed and embedded within the determination making framework. Multiple mannequin may be deployed to make sure a secure transition between the previous and new fashions.

Inquisitive about implementing a machine studying pipeline into your working movement?
Machine studying pipeline in manufacturing
When the mannequin coaching is completed, the subsequent step is to deploy it to the manufacturing surroundings, the place the mannequin will make its predictions on the actual information, making actual industrial results. The essential step right here is deployment, however efficiency monitoring can be one thing that must be carried out frequently.
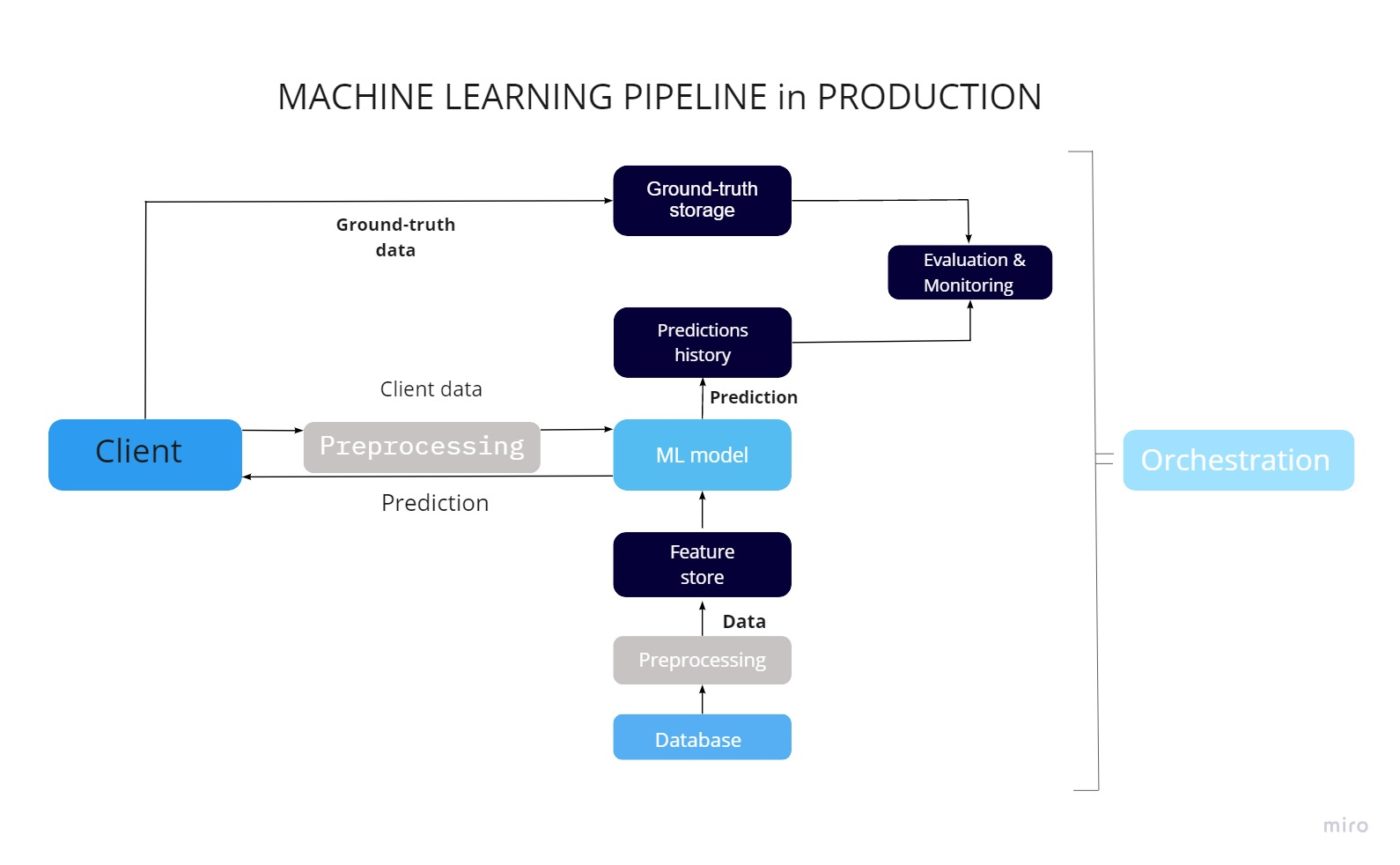
Management over the fashions, in addition to their efficiency, is crucial for the machine studying pipeline. Let’s check out the final structure, divide the method into particular actions, and make an outline of the primary instruments used for specific operations. Please notice that there are numerous varieties of machine studying techniques, and we’re speaking right here primarily based on our expertise. We hope that you should have a common thought of how machine studying techniques work by the tip.
Entry to the mannequin prediction information through the appliance
Let’s assume one has an utility that both interacts with the purchasers or different elements of the system. On this case, entry to the information will likely be attainable as soon as sure enter information will likely be offered. For instance, the same merchandise suggestions on the favored eCom marketplaces work in such means, the information about all of the visited merchandise is collected through the consumer journey via {the marketplace}, this information is distributed to the mannequin through API after which the response is given with the listing of merchandise that may be attention-grabbing for this specific shopper.
Function shops and the way they work
In some circumstances, the information can’t be instantly accessed, on this case, the characteristic shops may help. The instance of the information that may’t be instantly transferred utilizing the API is similar product advice system however primarily based on different customers’ tastes. We should always point out, that the amount of such information may be fairly massive, so listed here are two choices on tips on how to present it: batching and streaming.
Batching is mainly getting the data in parts, just like the pagination. Knowledge streaming alternatively is information streamed on the go and can be utilized for parcel monitoring, for instance, giving the estimation primarily based on the proper location of the supply automobile.
Knowledge preprocessing
The information comes from the appliance shopper in a uncooked format. This method permits the mannequin to learn this information; then it should be processed and transformed into capabilities in order that the mannequin can use it.
- The operate retailer also can have a devoted microservice for automated information preprocessing.
- Knowledge preprocessor: information despatched from the appliance shopper and performance retailer is formatted, capabilities are retrieved.
- Making forecasts: after the mannequin receives all of the required performance from the shopper and the operate retailer, it generates a forecast. It sends it to the shopper and a separate database for additional analysis.
Storing correct information and forecasts
It’s also important for us to obtain factual information from the shopper. Primarily based on them, the evaluation of the forecasts made by the mannequin and for its additional enchancment will likely be carried out. This type of info is normally saved in a database of legitimate information.
Nonetheless, it isn’t at all times attainable to gather truthful info in addition to automate this course of. Think about an instance, if a buyer bought a product from you, this can be a reality and may evaluate the mannequin’s predictions. And what if a shopper noticed your supply, however purchased from one other vendor, on this case, acquiring truthful info is inconceivable.
Mannequin analysis and monitoring
ML fashions deployed within the manufacturing surroundings must be monitored and evaluated consistently. To ensure the mannequin delivers the perfect outcomes we have to:
- Hold prediction outcomes to be as excessive as attainable.
- Analyze the mannequin efficiency.
- To have an understanding of the mannequin must be educated once more.
- To have a dashboard with the efficiency KPIs we’ve set.
Fairly a couple of open-source libraries accessible for visualization are the identical as some monitoring instruments (MLWatcher, for instance, for Python, permits it).
Orchestration
Orchestration is the automated placement, coordination, and administration of advanced laptop techniques. Orchestration describes how companies ought to work together with one another utilizing messaging, together with enterprise logic and workflow.
Thus, it offers full management over the deployment of fashions on the server, managing their operation, information movement administration, and activation of coaching/retraining processes.
Orchestrators use scripts to schedule and execute all the duties related to a manufacturing surroundings’s machine studying mannequin. Well-liked instruments used to orchestrate machine studying fashions are Apache Airflow, Apache Beam, and Kubeflow Pipelines.
Machine studying mannequin retraining pipeline
The information on which the fashions are educated are outdated because of this, the accuracy of the forecasts decreases. Monitoring instruments can be utilized to trace this course of. Within the case of critically low effectivity, it’s essential to retrain the mannequin utilizing the brand new information. This course of may be made automated.
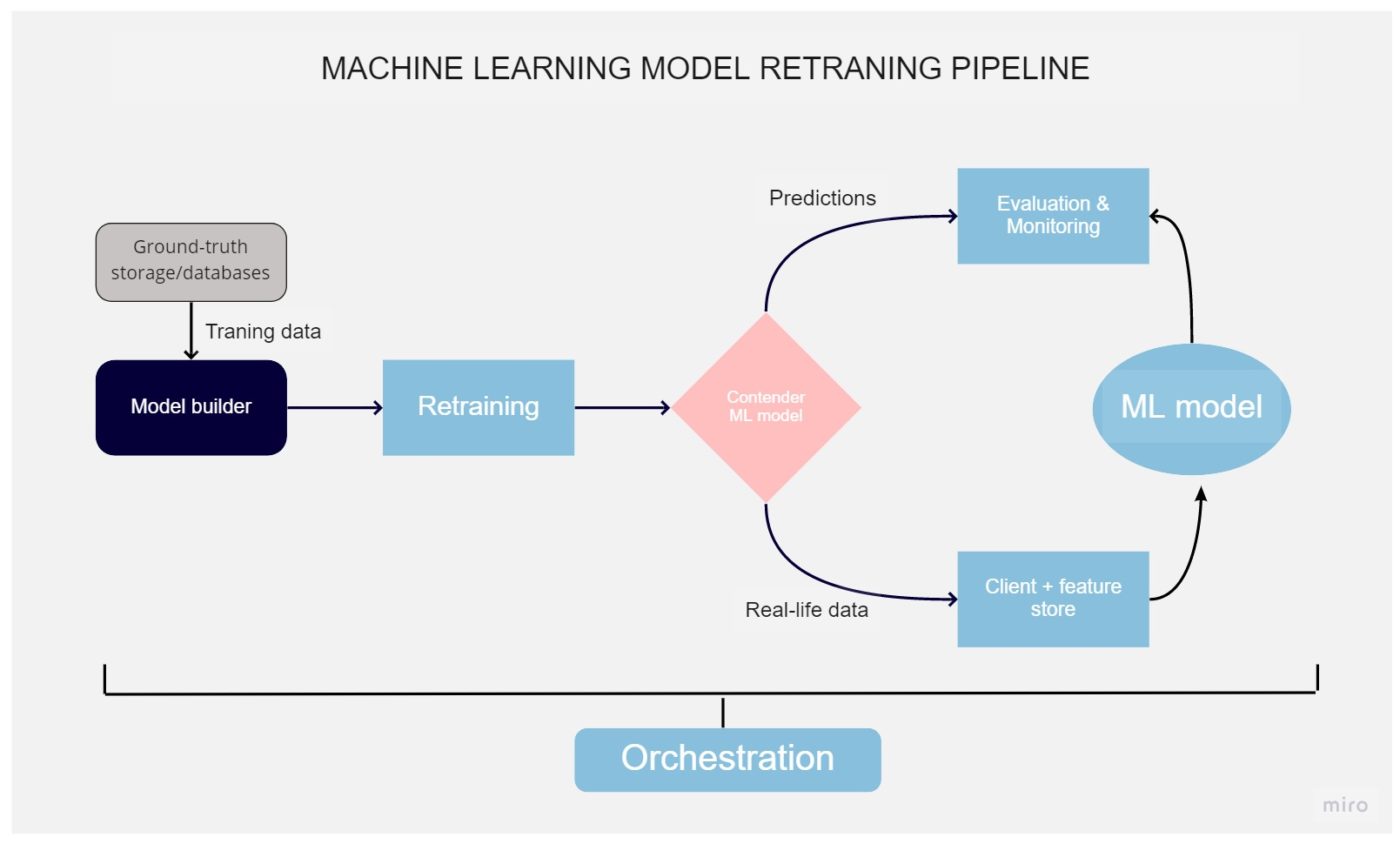
Mannequin retraining
The identical as coaching the mannequin, the retraining course of can be a vital a part of the entire life cycle. This course of makes use of the identical sources, like coaching, going via the identical steps till the deployment. Nonetheless, it’s required if the prediction accuracy decreased under the suitable stage that we monitor utilizing the strategies talked about earlier. This doesn’t essentially imply our mannequin works dangerous however can occur if some new options had been launched on a product that additionally must be included within the ML mannequin.
Retrained mannequin analysis
The mannequin educated on new information is designed to exchange the previous one, however earlier than that, it should be in contrast with elementary and different indicators, specifically accuracy, throughput, and so forth.
This process is carried out utilizing a novel software – an evaluator, which checks the mannequin’s readiness for manufacturing. It evaluates how correct the predictions are, and utilizing actual and dependable information, and it will probably solely evaluate educated fashions with already working fashions. Displaying the outcomes of the challenger mannequin occurs utilizing monitoring instruments. If a brand new mannequin performs higher than its predecessor, then it’s taken into manufacturing.
Wish to know how one can profit from ML pipeline?
Instruments for Machine Studying Pipeline creation
Machine Studying Pipeline is at all times a customized resolution, however some digital instruments and platforms may help you construct it. So let’s overview a few of them for a greater understanding of how they can be utilized.
| Steps For Constructing Machine Studying Pipeline | Instruments Which May be Used |
| Gathering Knowledge | Managing the Database – PostgreSQL, MongoDB, DynamoDB, MySQL.
Storage – Hadoop, Apache Spark/ Apache Flink. |
| Making ready Knowledge | The language for scripting – SAS, Python, and R.
Processing – MapReduce/ Spark, Hadoop. Knowledge Wrangling Instruments – R, Python Pandas |
| Exploring / Visualizing the Knowledge to seek out the patterns and traits | Python, R, Matlab, and Weka. |
| Modeling the information to do the predictions | Machine Studying algorithms – Supervised, Unsupervised, Reinforcement, Semi-Supervised and Semi-unsupervised studying.
Libraries – Python (Scikit study) / R (CARET) |
| Deciphering the consequence | Knowledge Visualization Instruments – ggplot, Seaborn, D3.JS, Matplotlib, Tableau |
Why is the machine studying pipeline vital?
Automating the mannequin life cycle phases is essentially the most essential characteristic of why the machine studying pipeline is used. With the brand new coaching information, a workflow begins with information validation, preprocessing, mannequin coaching, evaluation, and deployment. Performing all these steps manually is expensive, and there’s a risk of constructing errors. Subsequent, we wish to have a look at the advantages of utilizing machine studying pipelines:
- #1 Potential to give attention to new fashions with out supporting present fashionsAutomated machine studying pipelines negate the necessity to preserve present fashions, which saves time and doesn’t have to run scripts to preprocess the coaching information manually.
- #2 Stopping errorsIn handbook machine studying workflows, a standard error supply is altering the preprocessing stage after mannequin coaching. To keep away from this, you may deploy the mannequin with processing directions which might be completely different from these educated. These errors may be prevented through the use of automated workflows.
- #3 StandardizationStandardized machine studying pipelines improve the information scientist staff’s expertise and allow you to hook up with work and rapidly discover the identical growth environments. This improves effectivity and reduces the time spent organising a brand new mission.
The enterprise case for pipelines
The implementation of automated machine studying pipelines results in enhancements in 3 areas:
- Extra time to develop new fashions
- Simpler processes for updating present fashions
- Much less time spent enjoying fashions.
All these facets will cut back mission prices, and in addition to, it is going to assist detect potential biases in datasets or educated fashions. Figuring out bias can stop hurt to the folks interacting with the mannequin.
To conclude
Machine studying pipelines present many advantages, however not each information mission wants a pipeline. If you wish to experiment with how information works, then pipelines are ineffective in these circumstances. Nonetheless, as quickly because the mannequin has customers (for instance, it is going to be utilized in an utility), it is going to require fixed updates and fine-tuning.
Pipelines additionally turn out to be extra vital because the machine studying mission grows. If the dataset or useful resource necessities are giant, the approaches we talk about to make it straightforward to scale the infrastructure. If repeatability is crucial, that is achieved via the machine studying pipelines’ automation and audit path.
Get a free session on how one can streamline the enterprise processes with ML pipeline.
[ad_2]