
[ad_1]
The Subsequent Massive Step for Higher Knowledgeable Selections
Have you ever ever seen a dashboard and thought to your self that it will be good to have the ability to use machine studying to get extra out of your information? Properly, I’ve. I all the time had the concept when working with information, irrespective of the setting, it is best to have the ability to control it, to all the time see extra, and to be one step forward — dashboards included.
Nonetheless, there’s one small caveat on the subject of dashboards. They’re visited by individuals with varied expertise — information scientists, enterprise analysts, enterprise executives, and managers. Which means there isn’t any one-size-fits-all answer.
Proper now, I’m engaged on the personal beta for machine studying in dashboards, inside GoodData. At present, there are two attainable use circumstances on the desk:
- A one-click answer tailor-made for enterprise customers
- Palms-on expertise in Jupyter Pocket book for the tech-savvy
The one-click answer is fairly simple. Image this: you are a enterprise one that simply faucets a button, tweaks a few parameters for the algorithm, and voilà! You have obtained your self a forecast for subsequent quarter.

Is the One-Click on Method Excellent for Everybody?
No, after all not. The one-click expertise must be seen as a fast peek into the info relatively than a strong device. ML is usually very refined and requires many steps earlier than you may actually profit from it. While you enter rubbish, you get rubbish again. However hey, you may all the time roll up your sleeves, clear up that information, give it a bit polish, and set your self up for some smarter outputs.
To do that, it’s worthwhile to have the info readily available and know your method round it. Ideally, this will likely be a part of the transformation course of. However generally, you may’t change the info flows to the BI device. In that case, you may nonetheless fetch the info and use one thing like pandas in Python to get it into form.
For the second use case, if the one-click expertise is inadequate, you may open up a Jupyter pocket book instantly in your dashboard to work with the info firsthand. This implies you may retrieve a dataframe from any visualization and, as an example, change the ML algorithm or normalize the info beforehand.
Whereas working with the info, you may after all make the most of varied libraries to visualise it and work with it extra simply. Afterwards, you may ship the modified information again by the API to see it in your dashboard. That method, Jupyter notebooks break the boundaries between information visualization and information science, making machine studying not simply one other device, however an integral a part of knowledgeable resolution making.
For us, the guideline is accessibility for all, from newbies to seasoned information professionals. That is why our Jupyter notebooks are designed to comply with a ‘completely happy path,’ offering clear explanations at every step. This ensures that, proper out of the field, the outcomes you get from the notebooks align seamlessly with these from the one-click answer.
This built-in strategy eliminates the necessity for context-switching, permitting you to pay attention solely on the duty at hand. You may even have the pliability to preview your work at any stage and simply evaluate it with the present dashboard:

The notebooks additionally include a slight abstraction for the retrieval of dataframes and the follow-up push to the server. Knowledge lovers merely need to work with the info, and we need to assist them obtain this sooner. Retrieving and previewing the info body is as straightforward as working these Jupyter cells:

Pet Store Story
Let’s use a narrative to show how all this may come collectively.
You’re employed for a big pet retailer and your boss asks you to create a dashboard to point out him how nicely the shop is doing. As it’s a pet retailer, there may be some particular issues he’d wish to see, like indoor temperature or humidity. Sadly, your deadline is tonight.
Straightforward sufficient. You join your information supply (the place you combination all of your information) to some BI device and attempt to drag-and-drop your self out of hassle. Let’s say you could have Snowflake and use GoodData. This could make it straightforward to rapidly create a dashboard that appears like this:

Which may work, however your boss needs to see if there are any spikes in temperature, as a result of the parrots are inclined to sudden temperature adjustments. He want to see how the brand new kind of pet food may be priced, on account of financial adjustments. And he would additionally wish to see forms of patrons, as he want to higher tailor the subsequent low cost flyer.
You resolve to strive the one-click ML and hope for one of the best. You begin with pet food, and with two clicks you could have this visualization:

That appears fairly cheap, so you progress onto the temperature. However when taking a look at it, you discover there are some information factors lacking:

Properly, what are you able to do? A number of the algorithms fail on information with lacking values. Not all information is ideal, you may speak to your boss about it later. Because you need to see the temperature anomalies as quick as attainable, you open up the built-in Jupyter pocket book and use one thing like PersistanceAD from the adtk library:
df = get_df() # Merely fetch the dataframe
# ML parameters:
sensitivity = 1
window = 3
seasonal_ad = PersistAD(window = window, c=sensitivity, aspect="each")
anomalies = seasonal_ad.fit_detect(df)
This will get you an inventory of bools, denoting whether or not every level is an anomaly or not. Now you may need to visualize it utilizing matplotlib:
fig, ax = plt.subplots(figsize=(7, 2.5))
df.plot(ax=ax, label="information")
anomalies = anomalies.fillna(False)
# Filter the info utilizing the anomalies binary masks to get the anomaly values.
anomaly_values = df[anomalies]
# Use scatter to plot the anomalies as factors.
ax.scatter(anomaly_values.index, anomaly_values, colour="pink", label="anomalies")
ax.legend()

This isn’t actually telling, so that you play with the parameters for some time. And after a couple of minutes you’re performed! Now you may lastly see the factors you needed to see:

Lastly, you need to cluster the customers by shopping for energy, so your boss can lastly replace the outdated low cost flyer. For this you could have the next dataset:

This appears to be simply distinguishable with Okay-means or a Birch algorithm. You might have already used the Jupyter, so that you need to be accountable for this visualization. You begin the pocket book once more and run some variation of:
# Threshold for cluster proximity, decrease promotes splitting
threshold = 0.03
cluster_count = 5
# Replace DataFrame to be suitable with Birch
x = np.column_stack((df[df.columns[0]], df[df.columns[1]]))
mannequin = Birch(threshold=threshold, n_clusters=cluster_count)
yhat = mannequin.fit_predict(x)
Now you ship the yhat (the expected values) to the server. You might be rewarded with this visualization:
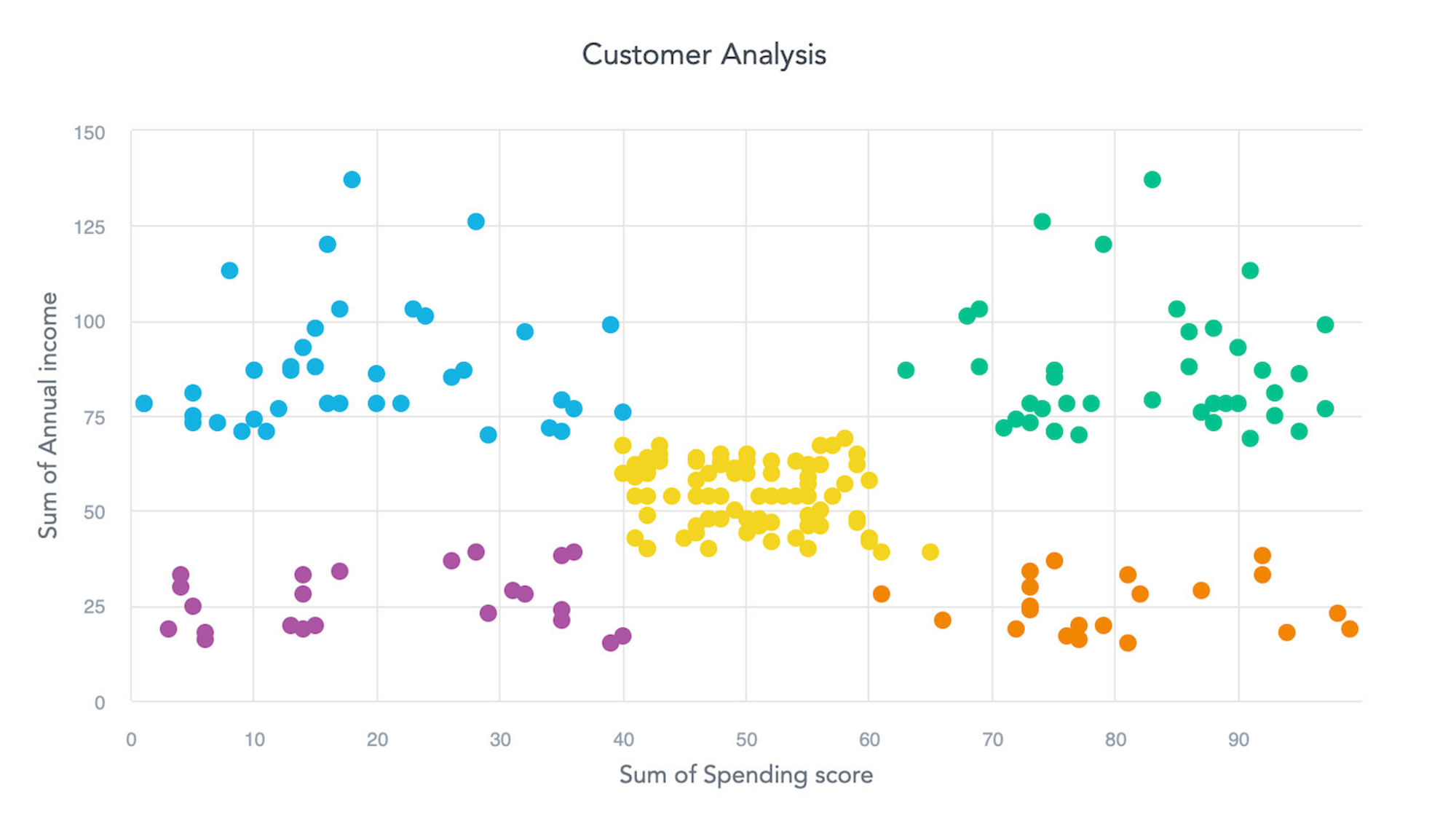
That actually appears to be like like a job nicely performed. To place it into context, let’s see how your complete dashboard appears to be like:

That’s it! You’ve managed to create the dashboard in time! And with this identical degree of ease, you may improve any a part of your dashboard to make it much more succesful than earlier than.
Conclusion
Machine studying is the subsequent logical step in maximizing the potential of your information, making it a vital characteristic in fashionable dashboards. Seamless implementation of machine studying is important to stop lack of context, guaranteeing that every one information exploration might be performed in a single place.
As of now, we’re aiming to create guided walkthroughs in Jupyter notebooks for the most well-liked visualizations. Which means most line plots and bar charts will quickly characteristic a pocket book for anomaly detection and forecasting. Scatter plots and bubble charts, alternatively, will give attention to clustering.
After all, the chances don’t finish there. Machine studying can improve practically any kind of knowledge, and when paired with AI, it may be directed by pure language queries. That is undoubtedly a promising avenue that we need to discover!
For those who’re fascinated about AI, take a look at this text by Patrik Braborec that discusses How you can Construct Knowledge Analytics Utilizing LLMs.
Would you wish to strive the machine studying enhanced dashboards? The options described on this article are at present being examined in a non-public beta, however if you wish to strive them, please contact us. You can even take a look at our free trial, or ask us a query in our group slack!
[ad_2]