 Dimension a Kubernetes Cluster for Effectivity")
[ad_1]
TL;DR: On this submit, you’ll discover ways to select the most effective node in your Kubernetes cluster earlier than writing any code.
Once you create a Kubernetes cluster, one of many first questions you’ll have is: “What sort of employee nodes ought to I exploit, and what number of of them?”
Or for those who’re utilizing a managed Kubernetes service like Linode Kubernetes Engine (LKE), do you have to use eight Linode 2 GB or two Linode 8 GB situations to attain your required computing capability?
First, not all assets in employee nodes can be utilized to run workloads.
Kubernetes Node Reservations
In a Kubernetes node, CPU and reminiscence are divided into:
- Working system
- Kubelet, CNI, CRI, CSI (and system daemons)
- Pods
- Eviction threshold
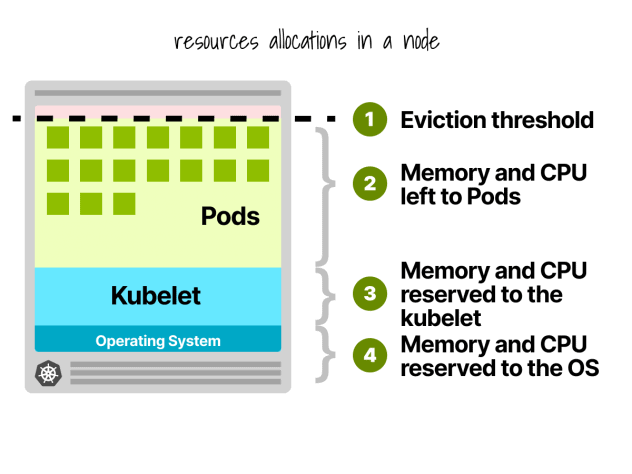
Let’s give a fast instance.
Think about you might have a cluster with a single Linode 2GB compute occasion, or 1 vCPU and 2GB of RAM.
The next assets are reserved for the kubelet and working system:
- -500MB of reminiscence.
- -60m of CPU.
On prime of that, 100MB is reserved for the eviction threshold.
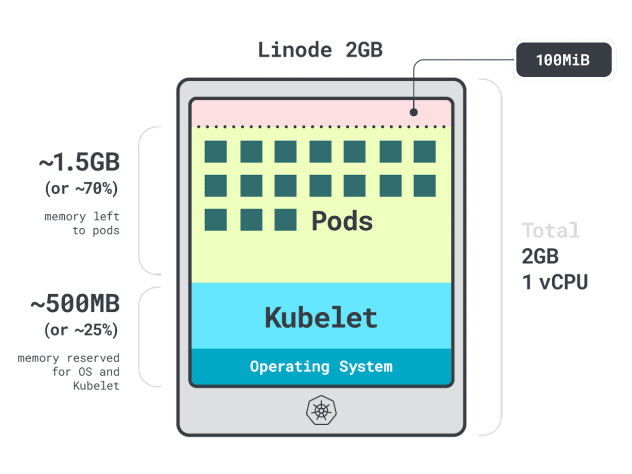
In complete, that’s 30% of reminiscence and 6% of CPU that you may’t use.
Each cloud supplier has its means of defining limits, however for the CPU, they appear to all agree on the next values:
- 6% of the primary core;
- 1% of the following core (as much as 2 cores);
- 0.5% of the following 2 cores (as much as 4); and
- 0.25% of any cores above 4 cores.
As for the reminiscence limits, this varies so much between suppliers.
However on the whole, the reservation follows this desk:
- 25% of the primary 4 GB of reminiscence;
- 20% of the next 4 GB of reminiscence (as much as 8 GB);
- 10% of the next 8 GB of reminiscence (as much as 16 GB);
- 6% of the following 112 GB of reminiscence (as much as 128 GB); and
- 2% of any reminiscence above 128 GB.
Now that you know the way assets are reparted inside a employee node, it’s time to ask the tough query: which occasion do you have to select?
Since there may very well be many right solutions, let’s prohibit our choices by specializing in the most effective employee node in your workload.
Profiling Apps
In Kubernetes, you might have two methods to specify how a lot reminiscence and CPU a container can use:
- Requests normally match the app consumption at regular operations.
- Limits set the utmost variety of assets allowed.
The Kubernetes scheduler makes use of requests to find out the place the pod ought to be allotted within the cluster. Because the scheduler doesn’t know the consumption (the pod hasn’t began but), it wants a touch. These “hints” are requests; you’ll be able to have one for the reminiscence and one for the CPU.
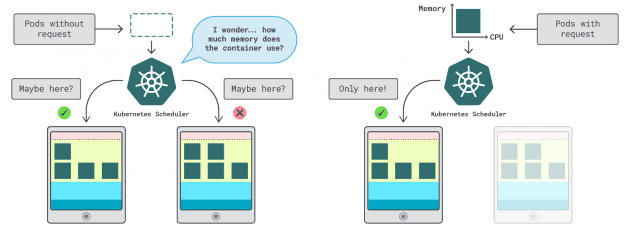
The kubelet makes use of limits to cease the method when it makes use of extra reminiscence than is allowed. It additionally throttles the method if it makes use of extra CPU time than allowed.
However how do you select the suitable values for requests and limits?
You’ll be able to measure your workload efficiency (i.e. common, ninety fifth and 99th percentile, and many others.) and use these as requests as limits. To ease the method, two handy instruments can velocity up the evaluation:
The VPA collects the reminiscence and CPU utilization information and runs a regression algorithm that implies requests and limits in your deployment. It’s an official Kubernetes venture and can be instrumented to alter the values mechanically– you’ll be able to have the controller replace the requests and limits straight in your YAML.
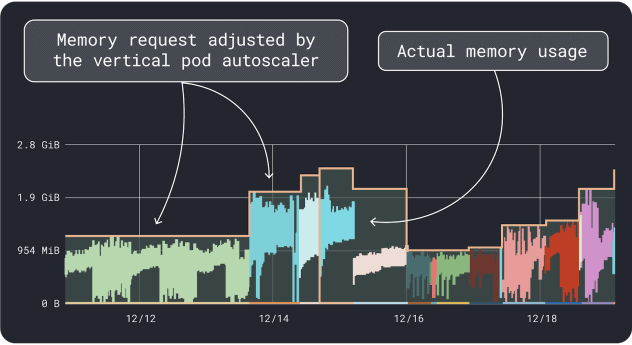
KRR works equally, however it leverages the information you export through Prometheus. As step one, your workloads ought to be instrumented to export metrics to Prometheus. When you retailer all of the metrics, you need to use KRR to research the information and counsel requests and limits.
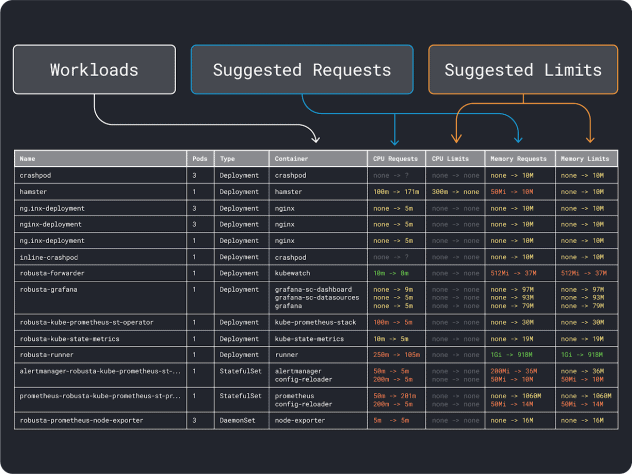
After getting an thought of the (tough) useful resource necessities, you’ll be able to lastly transfer on to pick out an occasion sort.
Choosing an Occasion Kind
Think about you estimated your workload requires 2GB of reminiscence requests, and also you estimate needing no less than ~10 replicas.
You’ll be able to already rule out most small situations with lower than `2GB * 10 = 20GB`. At this level, you’ll be able to guess an occasion that would work effectively: let’s choose Linode 32GB.
Subsequent, you’ll be able to divide reminiscence and CPU by the utmost variety of pods that may be deployed on that occasion (i.e. 110 in LKE) to acquire a discrete unit of reminiscence and CPU.
For instance, the CPU and reminiscence models for the Linode 32 GB are:
- 257MB for the reminiscence unit (i.e. (32GB – 3.66GB reserved) / 110)
- 71m for the CPU unit (i.e. (8000m – 90m reserved) / 110)
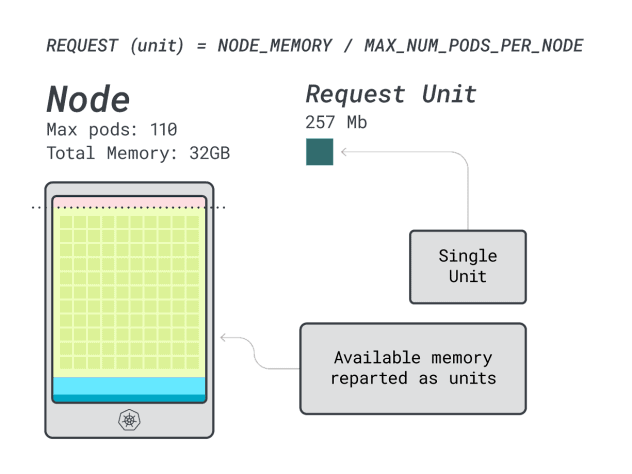
Glorious! Within the final (and remaining) step, you need to use these models to estimate what number of workloads can match the node.
Assuming you need to deploy a Spring Boot with requests of 6GB and 1 vCPU, this interprets to:
- The smallest variety of models that matches 6GB is 24 unit (24 * 257MB = 6.1GB)
- The smallest variety of models that matches 1 vCPU is 15 models (15 * 71m = 1065m)
The numbers counsel that you’ll run out of reminiscence earlier than you run out of CPU, and you’ll have at most (110/24) 4 apps deployed within the cluster.
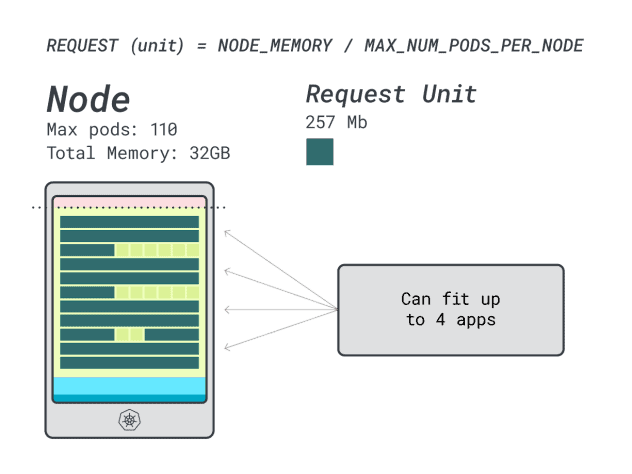
Once you run 4 workloads on this occasion, you utilize:
- 24 reminiscence models * 4 = 96 models and 14 are left unused (~12%)
- 15 vCPU models * 4 = 60 models and 50 are left unused (~45%)
Not unhealthy, however can we do higher?
Let’s attempt with a Linode 64 GB occasion (64GB / 16 vCPU).
Assuming you need to deploy the identical app, the numbers change to:
- A reminiscence unit is ~527MB (i.e. (64GB – 6.06GB reserved) / 110).
- A CPU unit is ~145m (i.e. (16000m – 110m reserved) / 110).
- The smallest variety of models that matches 6GB is 12 unit (12 * 527MB = 6.3GB).
- The smallest variety of models that matches 1 vCPU is 7 models (7 * 145m = 1015m).
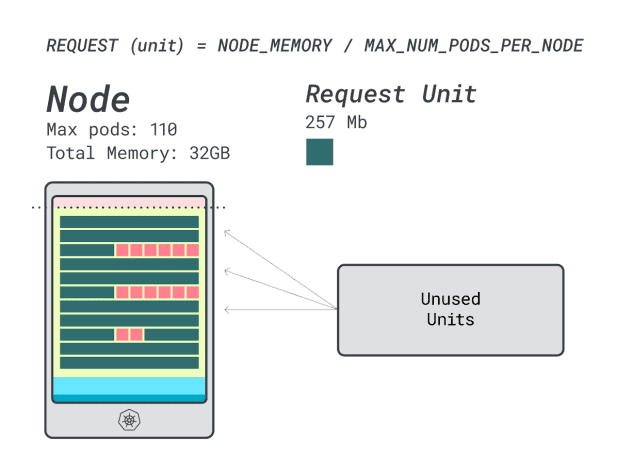
What number of workloads can you slot in this occasion?
Since you’ll max out the reminiscence and every workload requires 12 models, the max variety of apps is 9 (i.e. 110/12)
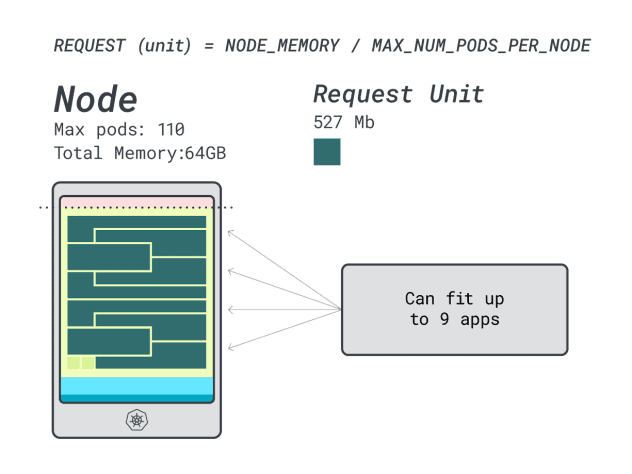
When you compute the effectivity/wastage, you will see that:
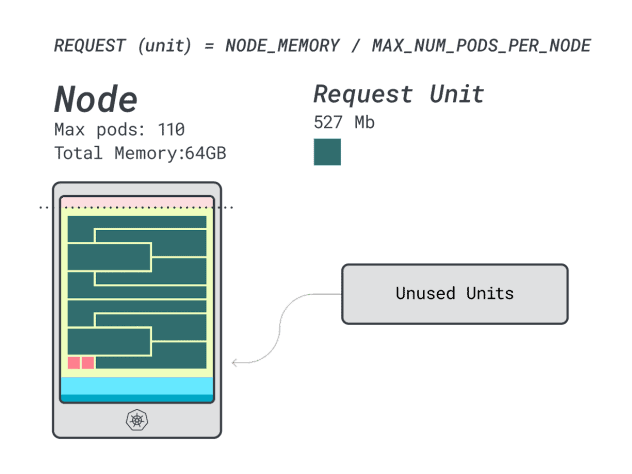
- 12 reminiscence models * 9 = 108 models and a couple of are left unused (~2%)
- 7 vCPU models * 9 = 63 models and 47 are left unused (~42%)
Whereas the numbers for the wasted CPU are nearly similar to the earlier occasion, the reminiscence utilization is drastically improved.
We are able to lastly examine prices:
- The Linode 32 GB occasion can match at most 4 workloads. At complete capability, every pod prices $48 / month (i.e. $192 price of the occasion divided by 4 workloads.)
- *The Linode 64 GB occasion can match as much as 9 workloads. At complete capability, every pod prices $42.6 / month (i.e. $384 price of the occasion divided by 9 workloads).
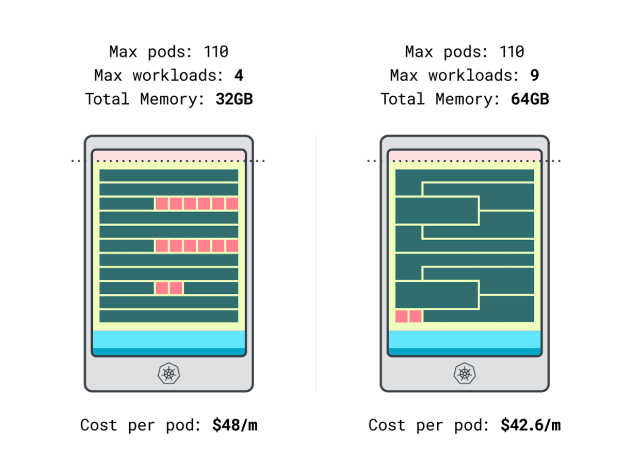
In different phrases, selecting the bigger occasion dimension can prevent as much as $6 monthly per workload. Nice!
Evaluating Nodes Utilizing the Calculator
However what if you wish to take a look at extra situations? Making these calculations is lots of work.
Velocity up the method utilizing the learnk8s calculator.
Step one in utilizing the calculator is to enter your reminiscence and CPU requests. The system mechanically computes reserved assets and suggests utilization and prices. There are some further useful options: assign CPU and reminiscence requests near the applying utilization. If the applying sometimes bursts into greater CPU or reminiscence utilization, that’s tremendous.
However what occurs when all Pods use all assets to their limits?
This might result in overcommitment. The widget within the heart provides you a share of CPU or reminiscence overcommitment.
What occurs once you overcommit?
- When you overcommit on reminiscence, the kubelet will evict pods and transfer them elsewhere within the cluster.
- When you overcommit on the CPU, the workloads will use the accessible CPU proportionally.
Lastly, you need to use the DaemonSets and Agent widget, a handy mechanism to mannequin pods that run on all of your nodes. For instance, LKE has the Cilium and CSI plugin deployed as DaemonSets. These pods use assets that aren’t accessible to your workloads and ought to be subtracted from the calculations. The widget helps you to do exactly that!
Abstract
On this article, you dived into a scientific course of to cost and determine employee nodes in your LKE cluster.
You realized how Kubernetes reserves assets for nodes and how one can optimise your cluster to make the most of it. Need to be taught extra? Register to see this in motion with our webinar in partnership with Akamai cloud computing providers.
[ad_2]