
[ad_1]
One of many main challenges in most enterprise intelligence (BI) tasks is knowledge high quality (or lack thereof). Actually, most undertaking groups spend 60 to 80 p.c of complete undertaking time cleansing their knowledge—and this goes for each BI and predictive analytics.
To enhance the effectiveness of the information cleansing course of, the present development is emigrate from handbook knowledge cleansing to extra clever, machine learning-based processes.
Determine the Lacking Information Values
Most analytics tasks will encounter three attainable sorts of lacking knowledge values, relying on whether or not there’s a relationship between the lacking knowledge and the opposite knowledge within the dataset:
- Lacking utterly at random (MCAR): On this case, there could also be no sample as to why a column’s knowledge is lacking. For instance, survey knowledge is lacking as a result of somebody couldn’t make it to an appointment, or an administrator misplaces the take a look at outcomes he’s imagined to enter into the pc. The explanation for the lacking values is unrelated to the information within the dataset.
- Lacking at random (MAR): On this state of affairs, the explanation the information is lacking in a column could be defined by the information in different columns. For instance, a faculty scholar who scores above the cutoff is usually given a grade. So, a lacking grade for a scholar could be defined by the column that has scores under the cutoff. The explanation for these lacking values could be described by knowledge in one other column.
- Lacking not at random (MNAR): Generally, the lacking worth is said to the worth itself. For instance, larger revenue folks could not disclose their incomes. Right here, there’s a correlation between the lacking values and the precise revenue. The lacking values are usually not depending on different variables within the dataset.
Easy methods to Deal with Lacking Information Values
Information groups can use a lot of methods to deal with lacking knowledge. On one hand, algorithms equivalent to random forest and KNN are sturdy in coping with lacking values.
However, you might have to take care of lacking knowledge by yourself. The primary widespread technique for coping with lacking knowledge is to delete the rows with lacking values. Usually, any row which has a lacking worth in any cell will get deleted. Nevertheless, this usually means many rows will get eliminated, resulting in lack of info and knowledge. Due to this fact, this technique is usually not used when there are few knowledge samples.
You too can impute the lacking knowledge. This may be based mostly solely on info within the column that has lacking values, or it may be based mostly on different columns current within the dataset.
Lastly, you should utilize classification or regression fashions to foretell lacking values.
Let’s take a look at these three methods in depth:
1. Lacking Values in Numerical Columns
The primary method is to exchange the lacking worth with one of many following methods:
- Change it with a continuing worth. This generally is a good method when utilized in dialogue with the area knowledgeable for the information we’re coping with.
- Change it with the imply or median. This can be a respectable method when the information measurement is small—but it surely does add bias.
- Change it with values through the use of info from different columns.
Within the worker dataset subset under, we’ve got wage knowledge lacking in three rows. We even have State and Years of Expertise columns within the dataset:
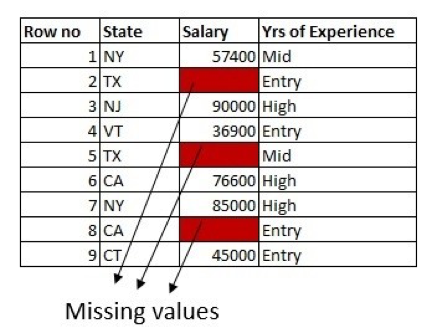
The primary method is to fill the lacking values with the imply of the column. Right here, we’re solely utilizing the data from the column which has lacking values:
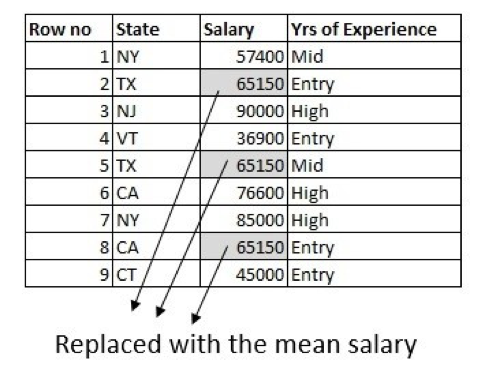
With the assistance of a site knowledgeable, we are able to do little higher through the use of info from different columns within the dataset. The common wage is totally different for various states, so we are able to use that to fill within the values. For instance, calculate the common wage of individuals working in Texas and exchange the lacking knowledge with a mean wage of people that sometimes work in Texas:
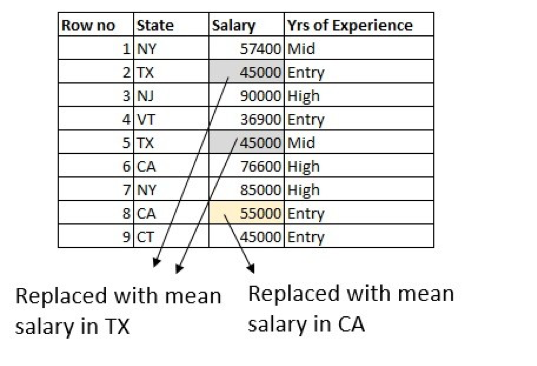
What else can we do higher? How about making use of the Years of Expertise column as effectively? Calculate the common entry-level wage of individuals working in Texas and exchange the row the place the wage is lacking for an entry-level individual in Texas. Do the identical for the mid-level and high-level salaries:
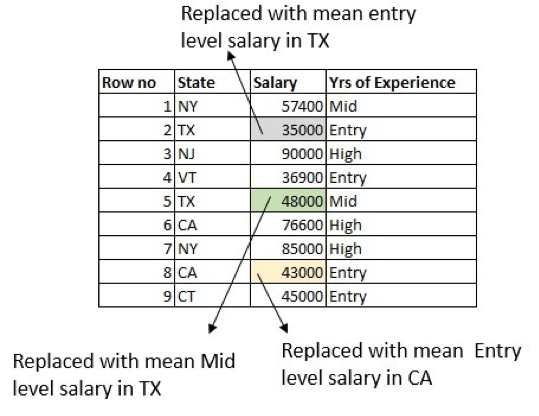
Be aware that there are some boundary situations. For instance, there may be a row that has lacking values in each the Wage and Years of Expertise columns. There are a number of methods to deal with this, however probably the most simple is to exchange the lacking worth with the common wage in Texas.
2. Predicting Lacking Values Utilizing an Algorithm
One other method to predict lacking values is to create a easy regression mannequin. The column to foretell right here is the Wage, utilizing different columns within the dataset. If there are lacking values within the enter columns, we should deal with these situations when creating the predictive mannequin. A easy method to handle that is to decide on solely the options that shouldn’t have lacking values, or take the rows that shouldn’t have lacking values in any of the cells.
3. Lacking Values in Categorical Columns
Coping with lacking knowledge values in categorical columns is quite a bit simpler than in numerical columns. Merely exchange the lacking worth with a continuing worth or the preferred class. This can be a good method when the information measurement small, although it does add bias.
For instance, say we’ve got a column for Training with two attainable values: Excessive College and School. If there are extra folks with a university diploma within the dataset, we are able to exchange the lacking worth with School Diploma:
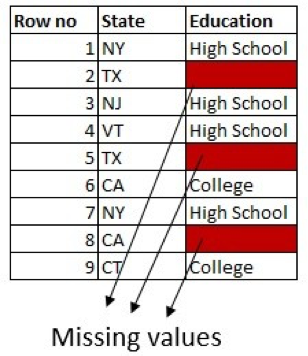
We are able to tweak this extra by making use of knowledge within the different columns. For instance, if there are extra folks from Texas with Excessive College within the dataset, exchange the lacking values in rows for folks from Texas with Excessive College.
One may create a classification mannequin. The column to foretell right here is Training, utilizing different columns within the dataset. However the most typical and common method is to mannequin the lacking worth in a categorical column as a brand new class known as Unknown:
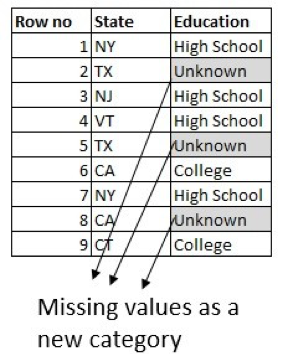
In abstract, you’ll use totally different approaches to deal with lacking knowledge values whereas knowledge cleansing relying on the kind of knowledge and the issue at hand. When you have entry to a site knowledgeable, at all times incorporate their knowledgeable recommendation when filling within the lacking values.
Most significantly, regardless of the imputation technique you select, at all times run the predictive analytics mannequin to see which one works greatest from the standpoint of information accuracy.

The Definitive Information to Predictive Analytics
Obtain Now:
[ad_2]