 Scaling: Combining Autoscalers")
[ad_1]
TL;DR: on this article, you’ll discover ways to proactively scale your workloads earlier than a peak in visitors utilizing KEDA and the cron scaler.
When designing a Kubernetes cluster, it’s possible you’ll have to reply questions reminiscent of:
- How lengthy does it take for the cluster to scale?
- How lengthy do I’ve to attend earlier than a brand new Pod is created?
There are 4 important elements that have an effect on scaling:
- Horizontal Pod Autoscaler response time;
- Cluster Autoscaler response time;
- node provisioning time; and
- pod creation time.
Let’s discover these one after the other.
By default, pods’ CPU utilization is scraped by kubelet each 10 seconds, and obtained from kubelet by Metrics Server each 1 minute.
The Horizontal Pod Autoscaler checks CPU and reminiscence metrics each 30 seconds.
If the metrics exceed the brink, the autoscaler will enhance the replicas depend and again off for 3 minutes earlier than taking additional motion. Within the worst case, it may be as much as 3 minutes earlier than pods are added or deleted, however on common, you need to anticipate to attend 1 minute for the Horizontal Pod Autoscaler to set off the scaling.

The Cluster Autoscaler checks whether or not there are any pending pods and will increase the dimensions of the cluster. Detecting that the cluster must scale up might take:
- As much as 30 seconds on clusters with lower than 100 nodes and 3000 pods, with a median latency of about 5 seconds; or
- As much as 60-second latency on clusters with greater than 100 nodes, with a median latency of about 15 seconds.
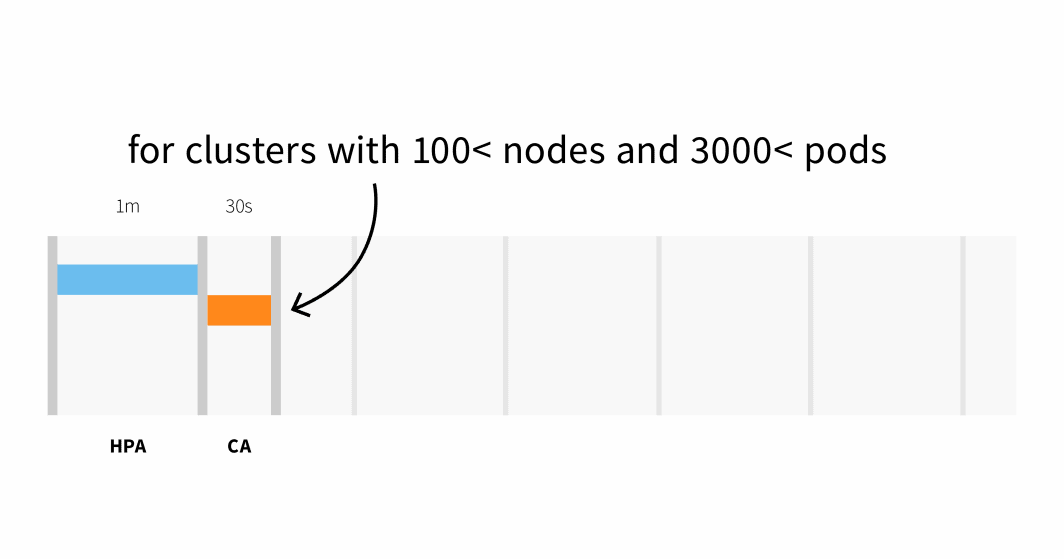
Node provisioning on Linode often takes 3 to 4 minutes from when the Cluster Autoscaler triggers the API to when pods will be scheduled on newly created nodes.
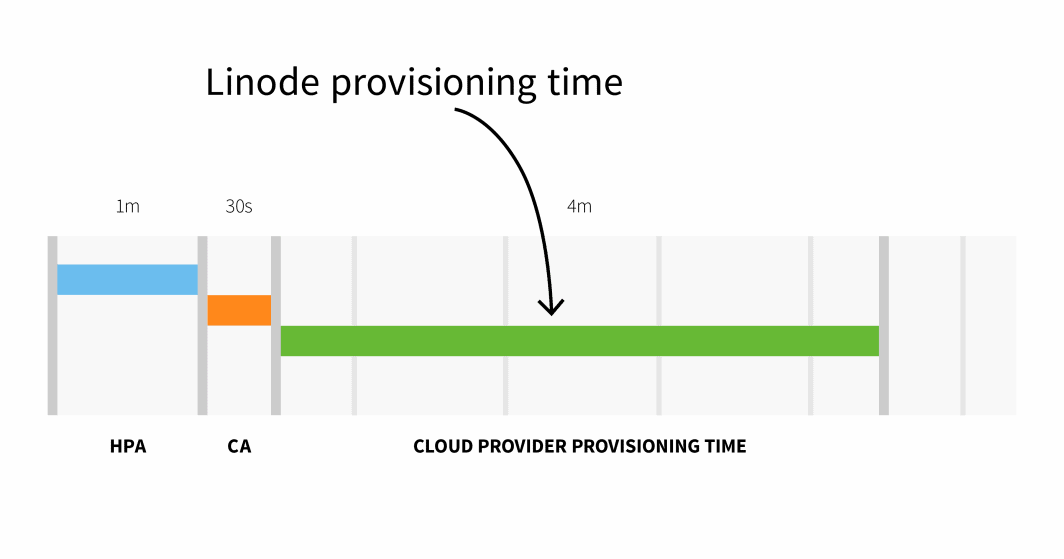
In abstract, with a small cluster, you could have:
```
HPA delay: 1m +
CA delay: 0m30s +
Cloud supplier: 4m +
Container runtime: 0m30s +
=========================
Complete 6m
```
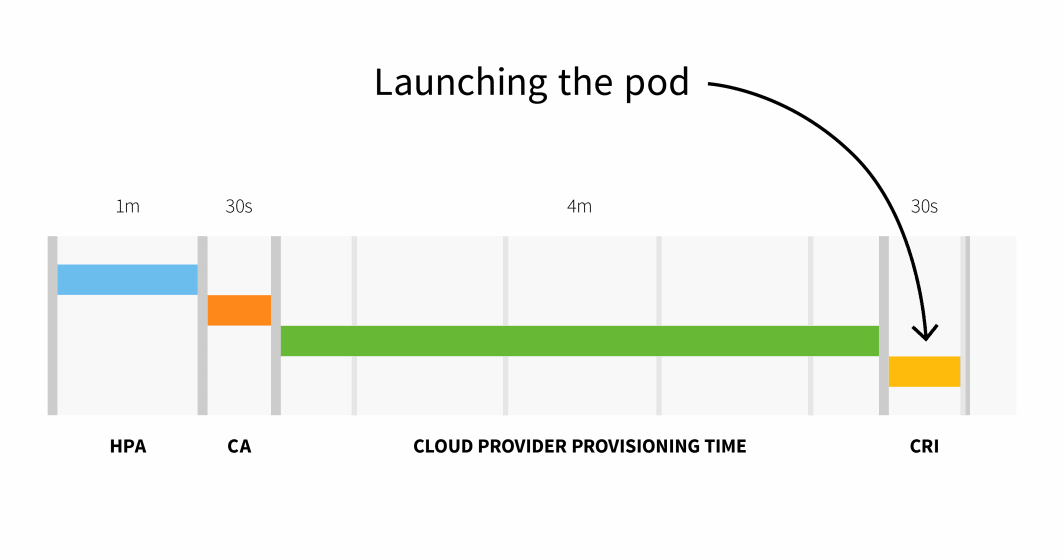
With a cluster with greater than 100 nodes, the entire delay could possibly be 6 minutes and 30 seconds… that’s a very long time, so how are you going to repair this?
You’ll be able to proactively scale your workloads, or if you understand your visitors patterns effectively, you may scale prematurely.
Preemptive Scaling with KEDA
When you serve visitors with predictable patterns, it is smart to scale up your workloads (and nodes) earlier than any peak and scale down as soon as the visitors decreases.
Kubernetes doesn’t present any mechanism to scale workloads based mostly on dates or occasions, so on this half, you’ll use KEDA– the Kubernetes Occasion Pushed Autoscaler.
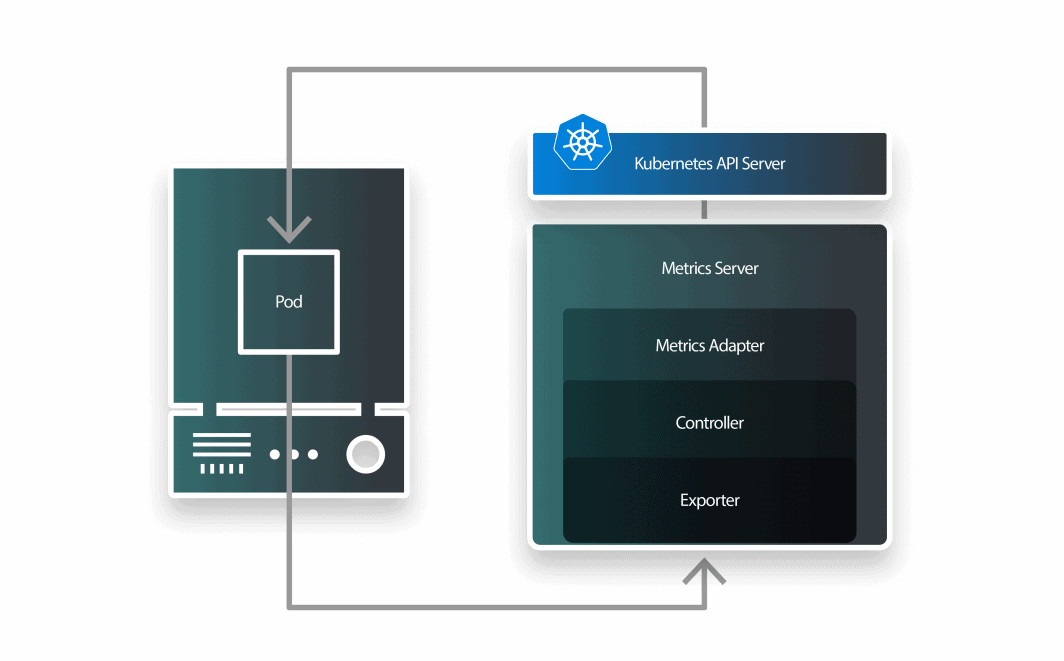
KEDA is an autoscaler manufactured from three parts:
- a scaler;
- a metrics adapter; and
- a controller.
You’ll be able to set up KEDA with Helm:
```bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm set up keda kedacore/keda
```Now that Prometheus and KEDA are put in, let’s create a deployment.
```yaml
apiVersion: apps/v1
form: Deployment
metadata:
identify: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- identify: podinfo
picture: stefanprodan/podinfoYou’ll be able to submit the useful resource to the cluster with:
```bash
$ kubectl apply -f deployment.yaml
```KEDA works on high of the present Horizontal Pod Autoscaler and wraps it with a Customized Useful resource Definition referred to as ScaleObject.
The next ScaledObject makes use of the Cron Scaler to outline a time window the place the variety of replicas ought to be modified:
```yaml
apiVersion: keda.sh/v1alpha1
form: ScaledObject
metadata:
identify: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
identify: podinfo
triggers:
- kind: cron
metadata:
timezone: Europe/London
begin: 23 * * * *
finish: 28 * * * *
desiredReplicas: "5"
```You’ll be able to submit the thing with:
```bash
$ kubectl apply -f scaled-object.yaml
```What is going to occur subsequent? Nothing. The autoscale will solely set off between 23 * * * * and 28 * * * *. With the assistance of Cron Guru, you may translate the 2 cron expressions to:
- Begin at minute 23 (e.g. 2:23, 3:23, and many others.).
- Cease at minute 28 (e.g. 2:28, 3:28, and many others.).
When you wait till the beginning date, you’ll discover that the variety of replicas will increase to five.
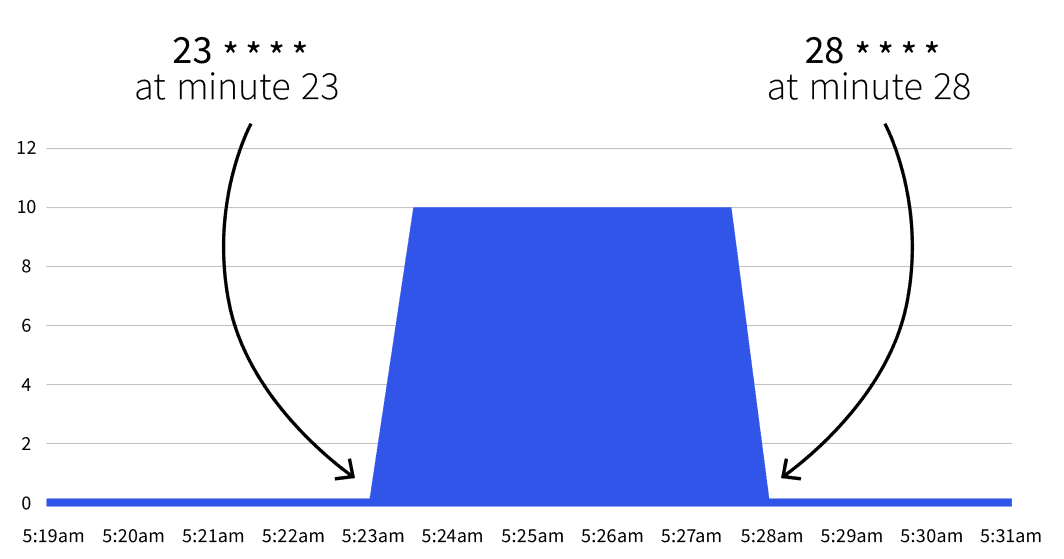
Does the quantity return to 1 after the twenty eighth minute? Sure, the autoscaler returns to the replicas depend laid out in minReplicaCount.
What occurs when you increment the variety of replicas between one of many intervals? If, between minutes 23 and 28, you scale your deployment to 10 replicas, KEDA will overwrite your change and set the depend. When you repeat the identical experiment after the twenty eighth minute, the duplicate depend can be set to 10. Now that you understand the idea, let’s have a look at some sensible use circumstances.
Scaling Down Throughout Working Hours
You will have a deployment in a dev surroundings that ought to be lively throughout working hours and ought to be turned off through the evening.
You could possibly use the next ScaledObject:
```yaml
apiVersion: keda.sh/v1alpha1
form: ScaledObject
metadata:
identify: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
identify: podinfo
triggers:
- kind: cron
metadata:
timezone: Europe/London
begin: 0 9 * * *
finish: 0 17 * * *
desiredReplicas: "10"
```The default replicas depend is zero, however throughout working hours (9 a.m. to five p.m.), the replicas are scaled to 10.
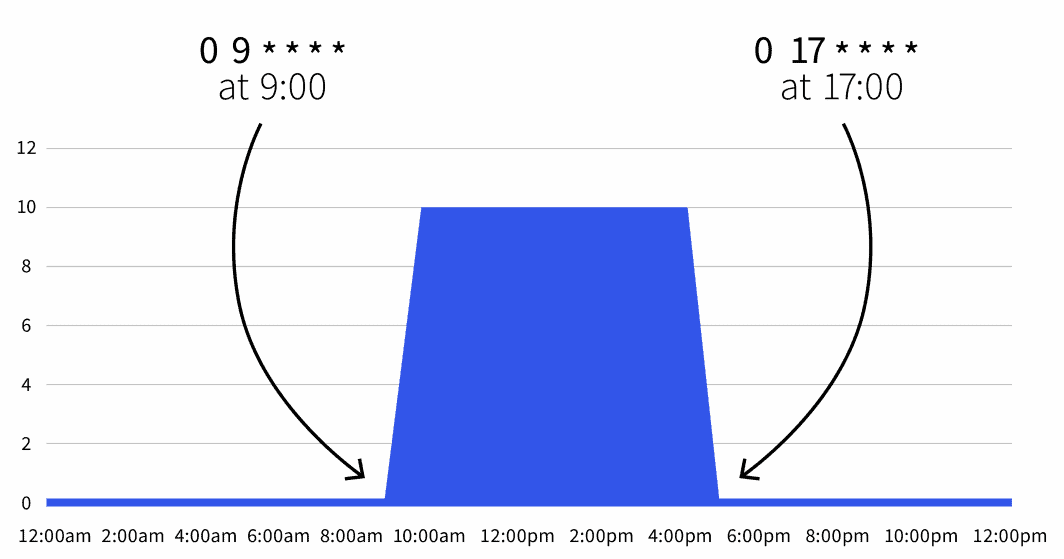
You can too increase the Scaled Object to exclude the weekend:
```yaml
apiVersion: keda.sh/v1alpha1
form: ScaledObject
metadata:
identify: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
identify: podinfo
triggers:
- kind: cron
metadata:
timezone: Europe/London
begin: 0 9 * * 1-5
finish: 0 17 * * 1-5
desiredReplicas: "10"
```Now your workload is just lively 9-5 from Monday to Friday. Since you may mix a number of triggers, you would additionally embody exceptions.
Scaling Down Throughout Weekends
For instance, when you plan to maintain your workloads lively for longer on Wednesday, you would use the next definition:
```yaml
apiVersion: keda.sh/v1alpha1
form: ScaledObject
metadata:
identify: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
identify: podinfo
triggers:
- kind: cron
metadata:
timezone: Europe/London
begin: 0 9 * * 1-5
finish: 0 17 * * 1-5
desiredReplicas: "10"
- kind: cron
metadata:
timezone: Europe/London
begin: 0 17 * * 3
finish: 0 21 * * 3
desiredReplicas: "10"
```On this definition, the workload is lively between 9-5 from Monday to Friday besides on Wednesday, which runs from 9 a.m. to 9 p.m.
Abstract
The KEDA cron autoscaler allows you to outline a time vary wherein you wish to scale your workloads out/in.
This helps you scale pods earlier than peak visitors, which can set off the Cluster Autoscaler prematurely.
On this article, you learnt:
- How the Cluster Autoscaler works.
- How lengthy it takes to scale horizontally and add nodes to your cluster.
- The best way to scale apps based mostly on cron expressions with KEDA.
Wish to be taught extra? Register to see this in motion throughout our webinar in partnership with Akamai cloud computing companies.
[ad_2]