 – Different – 2 Could 2023")
[ad_1]
Hello.
This take a look at will deploy a one dimensional “work” house with the native mql5 OpenCL instructions accessible .
The duty is to find find out how to map native reminiscence to work teams .
Frist let’s create a easy take a look at and try to gauge what the GPU does , or , how the GPU splits the workload with none directions if you’ll.
I do not know if it means something however that’s what i am looking for out.
Should additionally take into accout always and at each realization that this can be a particular response of this {hardware} so flexibility have to be in place for others (you) to check it by yourself .
OpenCL has some inbuilt indexes that may be referred to as from the kernel and can present the
- International id of the work merchandise , for a dimension
- Native id of the work merchandise , for a dimension
- Group id of the work merchandise , for a dimension
So we will reap the benefits of these indexes and see how the teams are organized if we dump quite a lot of duties on the GPU.
that is the kernel , the index calls have the dimension laid out in parentheses
string kernel="__kernel void memtests(__global int* global_id," "__global int* local_id," "__global int* group_id){" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}";
What this does is it receives 3 integer international reminiscence arrays global_id , local_id , group_id and fills them up with the related index on the international place . For instance if we had 10 oranges in 2 luggage we might assign the bag index to the linear array index of oranges .
We’d say , Orange[0] is in Bag0 and Orange[9] is in Bag1 , we might not use the index of the orange within the bag (Orange[0] is in Bag0 and Orange[4] is in Bag1) that might inform us nothing about how the oranges have been organized!
Therefore the usage of get_global_id(0) to retailer all ids.
We do all of the boring and annoying OpenCl prep stuff , how this system runs , when its referred to as , buffers kernels contexts and we offer one parameter for what number of objects or oranges to throw to the take a look at.
that is how the code seems to be :
#property model "1.00" int OnInit() { EventSetMillisecondTimer(33); return(INIT_SUCCEEDED); } void OnDeinit(const int motive) { } void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void memtests(__global int* global_id," "__global int* local_id," "__global int* group_id){" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int ker=CLKernelCreate(prg,"memtests"); if(ker!=INVALID_HANDLE){ int objects=2560; int global_ids[];ArrayResize(global_ids,objects,0); ArrayFill(global_ids,0,objects,0); int local_ids[];ArrayResize(local_ids,objects,0); ArrayFill(local_ids,0,objects,0); int group_ids[];ArrayResize(group_ids,objects,0); ArrayFill(group_ids,0,objects,0); int global_id_handle=CLBufferCreate(ctx,objects*4,CL_MEM_WRITE_ONLY); int local_id_handle=CLBufferCreate(ctx,objects*4,CL_MEM_WRITE_ONLY); int group_id_handle=CLBufferCreate(ctx,objects*4,CL_MEM_WRITE_ONLY); CLSetKernelArgMem(ker,0,global_id_handle); CLSetKernelArgMem(ker,1,local_id_handle); CLSetKernelArgMem(ker,2,group_id_handle); uint offsets[]={0}; uint works[]={objects}; CLExecute(ker,1,offsets,works); whereas(CLExecutionStatus(ker)!=CL_COMPLETE){Sleep(10);} Print("Kernel completed"); CLBufferRead(global_id_handle,global_ids,0,0,objects); CLBufferRead(local_id_handle,local_ids,0,0,objects); CLBufferRead(group_id_handle,group_ids,0,0,objects); int f=FileOpen("OCLlog.txt",FILE_WRITE|FILE_TXT); for(int i=0;i<objects;i++){ FileWriteString(f,"GLOBAL.ID["+IntegerToString(i)+"]="+IntegerToString(global_ids[i])+" : LOCAL.ID["+IntegerToString(i)+"]="+IntegerToString(local_ids[i])+" : GROUP.ID["+IntegerToString(i)+"]="+IntegerToString(group_ids[i])+"n"); } FileClose(f); int kernel_local_mem_size=CLGetInfoInteger(ker,CL_KERNEL_LOCAL_MEM_SIZE); int kernel_private_mem_size=CLGetInfoInteger(ker,CL_KERNEL_PRIVATE_MEM_SIZE); int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE); Print("Kernel native mem ("+kernel_local_mem_size+")"); Print("Kernel non-public mem ("+kernel_private_mem_size+")"); Print("Kernel work group measurement ("+kernel_work_group_size+")"); CLKernelFree(ker); CLBufferFree(global_id_handle); CLBufferFree(local_id_handle); CLBufferFree(group_id_handle); }else{Print("Can't create kernel");} CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Can't create ctx"); } } void OnTick() { }
Highlighted are the objects parameter and the export of the indices we acquired to a file .
Additionally this code prints 3 values :
- Kernel native reminiscence measurement (i get 1)
- Kernel non-public reminiscence measurement (i get 0)
- Kernel work group measurement (i get 256)
So let’s begin by throwing it 100 objects.
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 ... GLOBAL.ID[96]=96 : LOCAL.ID[96]=96 : GROUP.ID[96]=0 GLOBAL.ID[97]=97 : LOCAL.ID[97]=97 : GROUP.ID[97]=0 GLOBAL.ID[98]=98 : LOCAL.ID[98]=98 : GROUP.ID[98]=0 GLOBAL.ID[99]=99 : LOCAL.ID[99]=99 : GROUP.ID[99]=0
That is what the file output seems to be like (above) and you’ll see it didn’t cut up the work load in any means.
The very first thing that involves thoughts is “does it have a choice mechanism internally?” for each the wrapper and the mql5 native instructions after they get to name OpenCL instructions . How will we all know ? Let’s make the kernel a bit “heavier” and likewise extract a float worth .
Let’s create a spread of values from -2.6 to 2.6 and have it calculate the tanh of that x instances and likewise change the array on the spot.
So we add a world float pointer to the kernel arguments
__global float* _tangent,
Then we create a double array in our program fill it with random values in vary -2.6 to 2.6
float tangents[];ArrayResize(tangents,objects,0); float vary=5.2; for(int i=0;i<ArraySize(tangents);i++){ float r=(((float)MathRand())/((float)32767.0)*vary)-2.6; tangents[i]=r; }
Then create a buffer deal with for openCL ,on this case the reminiscence is learn write not simply write.(learn write for the machine not the host(us))
int tangents_handle=CLBufferCreate(ctx,objects*4,CL_MEM_READ_WRITE);
After which hyperlink the buffer to the kernel arguments
CLSetKernelArgMem(ker,3,tangents_handle);
aaand (i wasted 2 hours right here as i forgot to learn again the buffer 🤣) so , remember to name buffer learn if you need the information.
CLBufferRead(tangents_handle,tangents,0,0,objects);
aaand add free buffer on the finish in any other case it seems to be caching (neatly) the values
CLBufferFree(tangents_handle);
Cool , now , we have to make it a bit harder by offering an iterations quantity as an argument.
This can loop the tanh calculation and for every end result we will likely be summing up the tanh of the tangent float / iterations.
Neat.
On this case we have to add an argument within the kernel ,hyperlink the argument to the kernel and set the worth :
"int iterations){" int iterations=100; CLSetKernelArg(ker,4,iterations);
And the kernel calculations , let’s lookup the index of OpenCL
"float sum=(float)0.0;" "float of=(float)_tangent[get_global_id(0)];" "for(int i=0;i<iterations;i++){" "sum+=((float)tanh(of-sum))/((float)iterations);" "}" "_tangent[get_global_id(0)]=sum;"
- Set sum to 0.0;
- Set the preliminary worth in non-public mem variable “of”
- loop to iterations
- sum up the tanh of the “of” minus the sum up to now divided by the iterations.
- refill the tangent array
Easy and let’s set preliminary iterations to 100 and run the code once more to see if it nonetheless produces 1 group.(and likewise print the results of the sum to debug)
That is the exported file :
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=0.7702 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=0.0282 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : T[2]=0.9934 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : T[3]=2.2652 GLOBAL.ID[4]=4 : LOCAL.ID[4]=4 : GROUP.ID[4]=0 : T[4]=-2.2026 ... GLOBAL.ID[96]=96 : LOCAL.ID[96]=96 : GROUP.ID[96]=0 : T[96]=-1.7437 GLOBAL.ID[97]=97 : LOCAL.ID[97]=97 : GROUP.ID[97]=0 : T[97]=-1.1011 GLOBAL.ID[98]=98 : LOCAL.ID[98]=98 : GROUP.ID[98]=0 : T[98]=0.4125 GLOBAL.ID[99]=99 : LOCAL.ID[99]=99 : GROUP.ID[99]=0 : T[99]=1.8560
Okay it really works i believe , and we nonetheless get no cut up . Let’s jack up the iterations to 10000 however objects keep 100.
Nonetheless one group
GLOBAL.ID[99]=99 : LOCAL.ID[99]=99 : GROUP.ID[99]=0 : T[99]=0.0905
Let’s go nuts , 10 million iterations 100 objects , which may be problematic for the float precision ? let’s examine
No , nonetheless one group though the gpu delayed a bit.
GLOBAL.ID[99]=99 : LOCAL.ID[99]=99 : GROUP.ID[99]=0 : T[99]=-2.4797
(it is smart to not cut up in teams additional because the loop of iterations is a giant pile of calculations that require no reminiscence backwards and forwards so that is optimum for working in a processing aspect , but additionally i do not assume it will probably cut up throughout the work merchandise and the kernel is one work merchandise occasion if i am not mistaken . Transferring on.)
Cool , now let’s return the iterations to 1000 and begin testing with completely different merchandise quantities.
Let’s throw 200 objects to it
Nonetheless one group
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=1.5756 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=-1.1957 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : T[2]=0.6411 ... GLOBAL.ID[198]=198 : LOCAL.ID[198]=198 : GROUP.ID[198]=0 : T[198]=0.5839 GLOBAL.ID[199]=199 : LOCAL.ID[199]=199 : GROUP.ID[199]=0 : T[199]=-1.5742
Now let’s throw 257 objects !
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=2.0035 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=-0.0069 GLOBAL.ID[2]=2 : LOCAL.ID[2]=2 : GROUP.ID[2]=0 : T[2]=-0.8145 GLOBAL.ID[3]=3 : LOCAL.ID[3]=3 : GROUP.ID[3]=0 : T[3]=1.7880 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=255 : GROUP.ID[255]=0 : T[255]=0.2042 GLOBAL.ID[256]=256 : LOCAL.ID[256]=256 : GROUP.ID[256]=0 : T[256]=1.7910
Nonetheless no cut up.
How about 258 ? we get our first cut up !
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=-1.2919 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=-1.2212 ... GLOBAL.ID[127]=127 : LOCAL.ID[127]=127 : GROUP.ID[127]=0 : T[127]=-1.2222 GLOBAL.ID[128]=128 : LOCAL.ID[128]=128 : GROUP.ID[128]=0 : T[128]=1.9752 GLOBAL.ID[129]=129 : LOCAL.ID[129]=0 : GROUP.ID[129]=1 : T[129]=1.0197 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=126 : GROUP.ID[255]=1 : T[255]=1.9462 GLOBAL.ID[256]=256 : LOCAL.ID[256]=127 : GROUP.ID[256]=1 : T[256]=-1.9560 GLOBAL.ID[257]=257 : LOCAL.ID[257]=128 : GROUP.ID[257]=1 : T[257]=-0.9829
It cut up the work load in half in 2 teams !
Okay , so we’ve to search out the criterion for the cut up , let’s throw some numbers it likes 512 , 1024 , 2048 and so forth and log the outcomes.
512 : Splits in 2 teams once more :
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=-0.3564 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=2.3337 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=255 : GROUP.ID[255]=0 : T[255]=-2.4480 GLOBAL.ID[256]=256 : LOCAL.ID[256]=0 : GROUP.ID[256]=1 : T[256]=2.3620 ... GLOBAL.ID[510]=510 : LOCAL.ID[510]=254 : GROUP.ID[510]=1 : T[510]=-2.2709 GLOBAL.ID[511]=511 : LOCAL.ID[511]=255 : GROUP.ID[511]=1 : T[511]=-0.3056
Additionally discover how handy the native id is , its telling us the index in every group !
1024 : aha , it cut up into 4 teams now ! So is the utmost group measurement for this machine 256 objects ?
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=-0.7910 GLOBAL.ID[1]=1 : LOCAL.ID[1]=1 : GROUP.ID[1]=0 : T[1]=-0.7287 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=255 : GROUP.ID[255]=0 : T[255]=0.2203 GLOBAL.ID[256]=256 : LOCAL.ID[256]=0 : GROUP.ID[256]=1 : T[256]=1.4999 .. GLOBAL.ID[511]=511 : LOCAL.ID[511]=255 : GROUP.ID[511]=1 : T[511]=0.1762 GLOBAL.ID[512]=512 : LOCAL.ID[512]=0 : GROUP.ID[512]=2 : T[512]=-0.0072 ... GLOBAL.ID[767]=767 : LOCAL.ID[767]=255 : GROUP.ID[767]=2 : T[767]=-2.0688 GLOBAL.ID[768]=768 : LOCAL.ID[768]=0 : GROUP.ID[768]=3 : T[768]=-2.0622 ... GLOBAL.ID[1022]=1022 : LOCAL.ID[1022]=254 : GROUP.ID[1022]=3 : T[1022]=2.2044 GLOBAL.ID[1023]=1023 : LOCAL.ID[1023]=255 : GROUP.ID[1023]=3 : T[1023]=-0.6644
Let’s give it a 768 worth , does it like even group quantities ? (due to its cores quantity ?)
GLOBAL.ID[0]=0 : LOCAL.ID[0]=0 : GROUP.ID[0]=0 : T[0]=1.8908 ... GLOBAL.ID[255]=255 : LOCAL.ID[255]=255 : GROUP.ID[255]=0 : T[255]=0.0147 GLOBAL.ID[256]=256 : LOCAL.ID[256]=0 : GROUP.ID[256]=1 : T[256]=-1.5271 ... GLOBAL.ID[511]=511 : LOCAL.ID[511]=255 : GROUP.ID[511]=1 : T[511]=2.3339 GLOBAL.ID[512]=512 : LOCAL.ID[512]=0 : GROUP.ID[512]=2 : T[512]=-0.8512 ... GLOBAL.ID[767]=767 : LOCAL.ID[767]=255 : GROUP.ID[767]=2 : T[767]=-0.1783
Nope , no points there 3 teams of 256 objects every . Okay
Can we arrive at any conclusions right here ? is the worth :
int kernel_work_group_size=CLGetInfoInteger(ker,CL_KERNEL_WORK_GROUP_SIZE);
Informing us of the utmost work objects a piece group can have , as a result of , that’s what the gpu is doing by itself when it has no directions ?
And if that is true , what about this worth right here ?
int device_max_work_group_size=CLGetInfoInteger(ctx,CL_DEVICE_MAX_WORK_GROUP_SIZE);
in truth let me add it within the code and see what it returns :
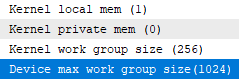
1024 it says . 1024 work teams or 1024 work objects in work teams whole ?
Properly , let’s discover out .
If we have been to get 1025 work teams (for this machine) we would want 1025*256 objects , that is 262400 objects .
Let’s have a look at . That is a giant a** file … however fortunately we solely want the final row.
Properly we get 1025 work teams … okay
GLOBAL.ID[262399]=262399 : LOCAL.ID[262399]=255 : GROUP.ID[262399]=1024 : T[262399]=-0.1899
Are we approaching this flawed ? it doesn’t must imply 1025 work teams executed in parallel proper ?
What if this means there will be 1024 work teams concurrently working as a result of this machine has 1024 compute models ?
Regardless that it reviews 1 compute unit (i am going to add these information instructions in too so you possibly can evaluate) and despite the fact that the cuda toolkit reviews 192 cuda cores and 32 warps .
This seems like :
- Nvidia half a**ed it
- OpenCL half a**ed it
- Mql5 half a**ed it
and we’re left holding the grenade attempting to determine if its a bunch of grapes or not.
However we do not like half a**ing issues we go full a** or no a**!
So , how can we inform what the f* is happening ?
We should measure time for execution , of what although ?
We have to uncover the numerous cutoff in execution time that signifies the cores are swapping teams , and , to complicate issues , this have to be versatile so in case you run it you could obtain a sign that when in comparison with my indications we will conclude or method the exercise within the machine.
Not my machine or your machine however normally.(if attainable)
Let’s additionally be aware that if a producer isn’t cooperating totally then there is no such thing as a different end result than 1/2*a**-ing it . So , mq and khronos are to not blame right here , to be truthful . So in that sense i have to put together to 0.5*a** it too. 😂
Okay , we now have to open an enormous parenthesis and do one thing else sadly .
The present benchmark has an issue in that its utilizing reminiscence so much .
If we would like the “cutoff” of the cores to seem we should use extra “calculations” than “fetching” .
This take a look at additionally executes as soon as we would like it to execute continually , there’s our second concern if the cutoff is
near our loop restarting we is not going to discover it!
Now you’re pondering what i am pondering : “why not resolve this on the decrease ranges , nvidia or amd” ? And the reply might be “we didn’t spend all this R+D cash for Khronos to come back out and achieve from it” , or , to simplify it “use Cuda , or , use Hpi” in all probability.
Much less rant extra code , or much less typing extra typing , moreover , complaining makes you wealthy solely if you’re a lawyer or a politician … 😂
Let’s go for it even when it fails
Benchmark 2 : execution time cutoff with group measurement
Let’s assume , how can we measure the time it takes ?
MQ has offered a strategy to execute a kernel as soon as i believe . Let’s verify actual fast .
Yeah , we will additionally ship measurement 0 and play with the offset so we keep away from the gpu cache .
Cool so , the benchmark will :
- load a calcs “heavy” kernel
- create a giant take a look at
- ship the objects one after the other asynchronously ???….
hmmmmm theres one other concern . We wish to discover the “bottleneck” of the GPU (or the machine) however OpenCL is not going to allow us to do this as it can deal with the load itself and we wont see something so , what number of kernels can we create ?
Can the benchmark be 1 thousand kernel handles their execution referred to as on the identical time (properly in a loop) after which we’ll begin receiving
time it takes for a kernel to finish ? sounds cheap . So to check open cl we’ll construct an open cl . A tiny open cl 😂

So what’s going to we want for the benchmark ?
- Kernels array
- Kernels begin time
- Kernels finish time
Then we’ll output the instances and determine find out how to proceed from there
Okay let’s write it and likewise do a primary take a look at working 5 kernels concurrently and with completely different knowledge!
Right here is the very first thing we code , can we run a number of situations of the identical kernel ? …
class kernel_info{ public: int offset; int deal with; ulong start_microSeconds; ulong end_microSeconds; kernel_info(void){reset();} ~kernel_info(void){reset();} void reset(){ offset=-1; deal with=INVALID_HANDLE; start_microSeconds=0; end_microSeconds=0; } void setup(int _hndl,ulong _start,int _offset){ deal with=_hndl; start_microSeconds=_start; offset=_offset; } void cease(ulong _end){ end_microSeconds=_end; } }; kernel_info KERNELS[]; int OnInit() { EventSetMillisecondTimer(33); return(INIT_SUCCEEDED); } void OnDeinit(const int motive) { } void OnTimer(){ EventKillTimer(); int ctx=CLContextCreate(CL_USE_GPU_DOUBLE_ONLY); if(ctx!=INVALID_HANDLE){ string kernel="__kernel void bench(__global int* global_id," "__global int* local_id," "__global int* group_id," "__global float* _tangent," "int iterations){" "float sum=(float)0.0;" "float of=(float)_tangent[get_global_id(0)];" "for(int i=0;i<iterations;i++){" "sum+=((float)tanh(of-sum))/((float)iterations);" "}" "sum=(float)0.12345;" "_tangent[get_global_id(0)]=0.123;" "global_id[get_global_id(0)]=get_global_id(0);" "local_id[get_global_id(0)]=get_local_id(0);" "group_id[get_global_id(0)]=get_group_id(0);}"; string errors=""; int prg=CLProgramCreate(ctx,kernel,errors); if(prg!=INVALID_HANDLE){ ResetLastError(); int kernels_to_deploy=5; int iterations=1000; ArrayResize(KERNELS,kernels_to_deploy,0); bool deployed=true; for(int i=0;i<kernels_to_deploy;i++){ KERNELS[i].deal with=CLKernelCreate(prg,"bench"); if(KERNELS[i].deal with==INVALID_HANDLE){deployed=false;} } if(deployed){ Print("Deployed all kernels!"); for(int i=0;i<kernels_to_deploy;i++){ if(KERNELS[i].deal with!=INVALID_HANDLE){Print("Kernel ["+i+"] Legitimate");} else{Print("Kernel ["+i+"] InValid");} } }else{ Print("Can't deploy all kernels!"); for(int i=0;i<kernels_to_deploy;i++){ if(KERNELS[i].deal with!=INVALID_HANDLE){Print("Kernel ["+i+"] Legitimate");} else{Print("Kernel ["+i+"] InValid");} } } for(int i=0;i<kernels_to_deploy;i++){ if(KERNELS[i].deal with!=INVALID_HANDLE){ CLKernelFree(KERNELS[i].deal with); } } CLProgramFree(prg); }else{Alert(errors);} CLContextFree(ctx); } else{ Print("Can't create ctx"); } }
Properly in fact we will that is what that is for 😅
Though i am detecting a little bit of lag .
Let’s jack this as much as 50 kernels and measure time between on timer begin and finish . With out doing anything simply mounting 50 kernels on OpenCL.
We transfer the quantity of kernels exterior of the if blocks , slap 2 timers on begin and finish and print the distinction :
lengthy timer_ended=GetTickCount(); lengthy diff=timer_ended-timer_started; if(timer_ended<timer_started){diff=UINT_MAX-timer_started+timer_ended;} Print("Time to load and unload "+IntegerToString(kernels_to_deploy)+" kernels = "+IntegerToString(diff)+"ms"); ExpertRemove();
and we run it once more for five kernels :
2023.05.02 20:11:41.352 blog_kernel_times_benchmark (USDJPY,H1) Time to load and unload 5 kernels = 94ms
kay now do 50 kernels
2023.05.02 20:12:15.704 blog_kernel_times_benchmark (USDJPY,H1) Time to load and unload 50 kernels = 78ms
superior , now do 50 kernels with a useless load (no cache)
2023.05.02 20:13:16.359 blog_kernel_times_benchmark (USDJPY,H1) Time to load and unload 50 kernels = 94ms
Wonderful no delays there . Let’s do bulk operations 5000 kernels . if we get 78ms we get the inexperienced gentle for the benchmark.
(there could also be a print delay although 😀 so print what isn’t deployed solely! and the standing)
2023.05.02 20:15:35.724 blog_kernel_times_benchmark (USDJPY,H1) Deployed all kernels! 2023.05.02 20:15:35.746 blog_kernel_times_benchmark (USDJPY,H1) Time to load and unload 5000 kernels = 94ms
Nice . lets go then !
We now want to show calculations within the kernel to : get worth , do insane quantity of calcs on it , give worth.
Now we have one situation that have to be met for the iterations :
The milliseconds it takes to execute ONE work unit have to be a sure magnitude larger than the timer interval in order that we will measure it !
So if the “benchmark” have been to search out the optimum iterations itself it will go right into a loop till the iterations it despatched are at “instances” larger than the interval.
Let me repeat what we’re doing right here : we wish to “catch” the “shift” change in processing components , that means , the second when the busy models unload and obtain new knowledge successfully , or so i believe , giving us the variety of processing components (i am guessing will probably be equal to
CL_DEVICE_MAX_WORK_GROUP_SIZE
What ?
Let me clarify what i believe can occur right here :
Now we have a compute unit with 10 processing sub cores (the processing components)
if i ship 10 kernels on the identical time for execution i’ll get 150milliseconds execution time total , that means , my minimal recorded time throughout the kernel information objects subtracted from the utmost recorded time will likely be 150milliseconds.
Now if i run 11 kernels and that i discover ~300milliseconds that tells me one thing proper vs if i discovered 170milliseconds .
Proper ? i may be flawed .

Lets see ! that is enjoyable ! 😍
[ad_2]